목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries 일명 DETR3D입니다. DETR3D는 2020년 facebook research팀에서 발표한 DETR에서 인사이트를 얻어 발표한 논문입니다. DETR에서는 transformer 구조를 활용하여 2D OD(object detection)을 진행하지만, 본 논문에서는 transformer 구조를 활용하여 3D OD를 진행합니다.
제가 이 논문을 리뷰하게된 가장 큰 이유는 Depth Estimation을 통해 3D 입력값을 얻고 3D OD를 진행하는 기존 방식과 달리 Multi-view image와 카메라의 Projection matrix(Intrinsic, Extrinsic)을 이용하여 3D 공간상에서 직접 3D OD를 수행하는 매우 신박한 방법을 제안했기 때문입니다.
어떻게 여러장의 2D 이미지만으로 3D OD를 수행했는지 알아보겠습니다.
1. Introduction
기존에도 3D OD를 수행하기 위한 많은 연구가 있었습니다. CenterNet과 FCOS와 같이 2D OD를 위해 설계된 아키텍처를 사용하여 2D OD 결과를 통합하여 3D OD를 수행하는 연구들이 있었습니다. 그러나 이런 방식은 여러 이미지에서 생성된 예측결과를 통합하고, 중복된 예측결과를 제거해야하는 후처리과정이 필요하여 많은 computation cost를 필요로 한다는 문제점을 갖고있었습니다.
이와달리 Depth Estimation을 활용하여 3D 입력값을 획득하고 3D OD를 수행하는 연구도 존재했습니다. 그러나 이러한 연구들은 Depth Estimation 과정에서 잘못 수집된 깊이값이 3D OD 검출 성능에 부정적인 영향을 미치는 문제를 갖고있었습니다. Depth Estimation task를 진행해본 사람이라면 누구나 알고있겠지만, Depth Estimation Error는 거리에 따라 Exponential하게 증가합니다. 이러한 Depth error가 누적되면 결과적으로 3D OD 예측결과도 많은 error가 발생하게 됩니다. 또한 Depth Estimation이 어려운 상황(occlusion) 성능이 떨어지는 문제점을 갖고있었습니다.
그래서 본논문에서는 2D OD결과를 통합하거나 Depth Estimation을 수행하지 않습니다. 대신 Back-projection 기법을 활용하여 3D OD를 수행합니다. 수행과정을 간단하게 설명하면 다음과 같습니다.
- ResNet backbone을 활용하여 2D 이미지들로부터 Feature map 추출
- Feature map으로부터 Object Priors(객체에 대한 사전지식)을 학습
- Object Priors를 학습한 쿼리를 참조점(reference point)로 변환
- 카메라 Projection matrix(Intrinsic, Extrinsic)를 활용하여 참조점을 Feature map에 Back-projection
- Feture map에서 참조점이 찍힌 위치의 2D feature 추출
- 2D feature들을 쿼리들에 더하기
- 쿼리들을 MHSA(Multi-head Self-attention)층에 입력하여 Global한 feature를 인코딩
- 마지막으로 FCN으로 구성된 Detection Head에서 3D BBox 생성
이러한 방법으로 NMS와 같은 후처리과정을 생략하여 기존 방법보다 추론속도를 크게 향상시킬 수 있었고, Depth Estimation 과정을 생략하여 깊이 추정 오류에 강인한 모델을 개발하였다고 합니다.
2. Related Work
이 부분에서는 2D OD, Set-based OD, Monocular 3D OD에 관한 배경지식을 제공합니다.
2D Object Detection
- RCNN 계열 2-stage object detection 모델에 대해 설명합니다.
- ssd, yolo와 같은 1-stage object detection 모델에 대해 설명합니다.
- CenterNet과 FCOS와 같은 픽셀단위 예측 모델에 대해 설명합니다.
Set-based Object Detection
- DETR은 transformer 구조를 활용하므로 많은 학습데이터와 학습시간이 필요한 문제점이 있었음
- 이러한 문제를 해결하기 위해 Deformable Attention을 활용하는 Deformable DETR이 제안됨
Monocular 3D Object Detection
- 단일 2D 이미지로부터 3D object detection을 수행하는 방법에 대해 설명합니다.
3. Multi-view 3D Object Detection
3.1 Overview

DETR3D는 Multi-view RGB 이미지들과 각 카메라의 Projection matrix(Intrinsic, Extrinsic)를 입력값으로 받습니다. 전체적인 아키텍처는 크게 3가지 모듈로 구성됩니다.
- Backbone: 2D 이미지로부터 Feature map을 생성하는 모듈입니다. 본 논문에서는 ResNet-101과 FPN을 사용하였습니다.
- Detection Head: 2D feature로부터 3D BBox를 생성하는 모듈입니다. 이를 위해 Transformer 구조와 3D 쿼리를 사용하였습니다.
- Loss: DETR 논문에서 사용한 Set-to-set Loss를 사용해서 각 쿼리에 대한 예측결과를 생성하는 모듈입니다.
3.2 Feature Learning
DETR3D 모델의 Backbone은 ResNet-101과 FPN으로 구성되어 있으며, 하나의 이미지로부터 총 4장의 Multi-scale feature map이 생성됩니다. 모델은 학습을 위해 총 4가지 입력값을 필요로 합니다.
- 카메라로부터 수집된 이미지: I (nuScenes 데이터셋의 경우 각 6장)
- Camera 행렬: T (총 6개 행렬, 각 행렬의 크기는 3x4)
- GT Bounding Box: B (총 m개이며, Bird Eye View에서 객체의 중심위치, 객체의 크기, 객체가 바라보고 있는 방향의 각도, 객체의 이동속도 를 포함)
- Class Label: C (총 m개)
모델은 이러한 실제 경계상자의 위치를 정확히 예측하는 것을 목표로 학습됩니다.
3.3 Detection Head

DETR3D Head는 Transformer 구조를 활용합니다. 여기서는 총 4단계에 걸쳐 2D feature로부터 3D BBox를 생성합니다.
- 객체 쿼리와 연관된 3D 참조점(경계 상자 중심)의 집합을 예측합니다.
- 3D 참조점을 카메라 변환 행렬을 사용하여 Feature map에 Back-projection 합니다.
- 특징들을 Bilinear Interpolation(이중 선형 보간)을 통해 샘플링하고 이를 객체 쿼리에 통합합니다.
- 쿼리들 간에 Multi-head Self-attention을 수행하여 객체 쿼리를 개선(Refinement)합니다.
이렇게 설명하면 직관적으로 잘 이해가 가지않는데요. 하나하나 자세히 살펴보겠습니다.
1단계에서는 모델이 이미지에서 객체가 있을 가능성이 높은 위치, 즉 3D 참조점(객체 경계 상자의 중심)을 예측합니다. 이는 객체쿼리(object query)를 통해 이루어지는데요.
객체 쿼리(object query)란?
:객체 쿼리는 고차원 특징 벡터로서 "학습 가능한" 파라미터입니다.
DETR3D 모델의 transformer 디코더에서 Feature map뿐만 아니라 객체 쿼리까지 활용하여 객체의 위치를 찾는 이유는 다음과 같습니다.
- 지역정보 활용: 객체 쿼리를 사용하면 transformer 디코더가 특정한 객체나 영역에 집중할 수 있습니다.
이는 전역적인(feature map 전체) 정보를 사용하는 것보다 특정 객체에 대한 정보를 더 효과적으로 추출할 수 있습니다.
- 학습 효율성: 객체 쿼리를 사용하면 디코더가 빠르게 수렴할 수 있습니다.
이는 Transformer 기반 모델이 초기 학습단계에서 전역적 Attention을 통해 지역적 객체 정보를 학습하는데 많은 시간이 걸리는 문제를 해결할 수 있습니다.
참조: Mask2Former 논문객체 쿼리로부터 3D 참조점을 예측할 때 아래의 수식이 사용됩니다.

- qli: 하나의 쿼리(각 쿼리는 c차원 벡터)
- l: Transformer 층번호
- i: 쿼리 번호
- Φref는 NN(Neural Network)
결과적으로 우리는 3차원 좌표, 즉 3D 참조점 cli를 얻을 수 있습니다.
2단계에서는 앞서 얻은 3D 참조점을 Feature map에 Back-projection 합니다. 3D 참조점을 Back-projection을 할때 아래의 수식이 사용됩니다.

- ⊕: Concatenation
- Tm: Camera Transformation matrix
- m: 카메라 번호
결과적으로 우리는 3D 참조점 cli를 Feature map에 Back-projection한 좌표 clmi를 얻게됩니다.
(이때, c*li를 구하기 위해 cli와 1을 concat은 왜하는 걸까요? 계산상의 편의을 위해 3D 참조점 cli를 동차 좌표계로 변환하기 위해서 입니다. 동차 좌표계란 기하학에서 3D 좌표를 4D 좌표로 확장하는 방법입니다. 이를 통해 점의 위치를 나타내는데 있어 보다 편리하게 계산이 가능합니다.)
3단계에서는 Feature map으로부터 Feature들을 Sampling합니다. 이 때 Bilinear Interpolation(이중 선형 보간)을 수행하고 아래의 수식이 사용됩니다.

- Fkm: m번째 카메라의 k번째 feature map
결과적으로 우리는 Transformer l번째 층의 i번째 쿼리로부터 선택받은 m번째 카메라 이미지의 k번째 feature map에서 샘플링된 feature인 flkmi를 얻게됩니다.(굉장히 기네요....)
최종 Feature인 fli를 구할 때 아래 수식이 사용됩니다.
잘 생각해보면 특정한 3D 참조점이 모든 이미지에 Back-projection되지 않습니다. 그래서 저자는 이러한 경우를 다루기 위해 0과 1을 갖는 σlkmi를 도입하였습니다. 3D 참조점이 해당 이미지에 Back-projection되면 1, 아니면 0값을 갖습니다. 아래 식을 이용하면 여러 개의 Feature map에서 구한 여러 개의 Feature들을 통합하고 최종 Feature Fli를 구할 수 있습니다.
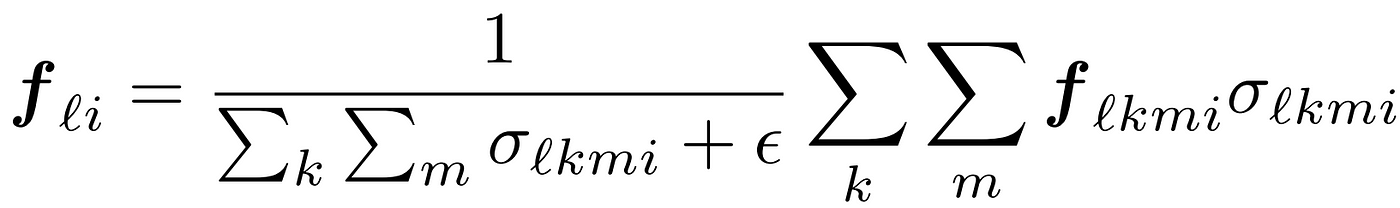
이렇게 얻어진 최종 feature fli를 다시 쿼리에 포함시키는 작업을 진행해야 합니다. 이때 아래 수식이 사용됩니다.

4단계에서는 2D feature가 합쳐진 쿼리들을 Multi-head Self-attention Block에 입력하여 개선시킵니다.
이 과정을 통해 쿼리들끼리 상관관계를 반영한 더 정확한 쿼리를 얻게 됩니다.
마지막으로 이렇게 개선된 각 쿼리 qli를 사용해서 3D Bounding Box는 어떻게 생성할까요? 방법은 다음과 같습니다.
왼쪽 식을 사용하여 Bounding Box를 생성하고, 오른쪽 식을 사용하여 Class Score를 구합니다.

- Φreg, Φcls: NN(Neural Network)
Neural Network의 아래첨자 부분에 l이란 값이 존재하는데 이는 Neural Network의 층수를 말하고, 즉 Transformer의 각 층마다 개별적인 Neural Network를 사용한다는 것을 의미합니다.

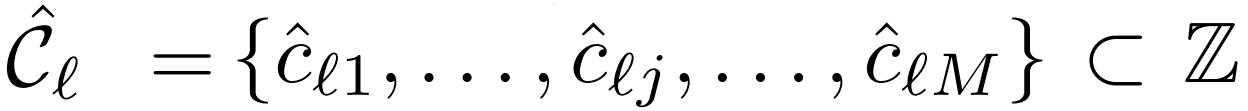
3.4 Loss
본 논문에서는 예측값과 GT 사이의 차이를 계산하기 위해 Set-to-set Loss를 사용합니다. 이 Loss는 두 부분으로 이루어져 있습니다.
- Class label에 대한 Focal loss
- Bounding box parameter에 대한 L1 loss
두가지 Loss를 계산하기에 앞서 한가지 문제점이 존재합니다. 바로 GT의 경계상자 수 M은 일반적으로 예측된 경계상자의 수 M^ 보다 적다는 건데요. 그래서 계산의 편의를 위해 GT 경계 상자의 수를 M^과 맞춰주기 위해 ∅(객체 없음)로 패딩합니다.
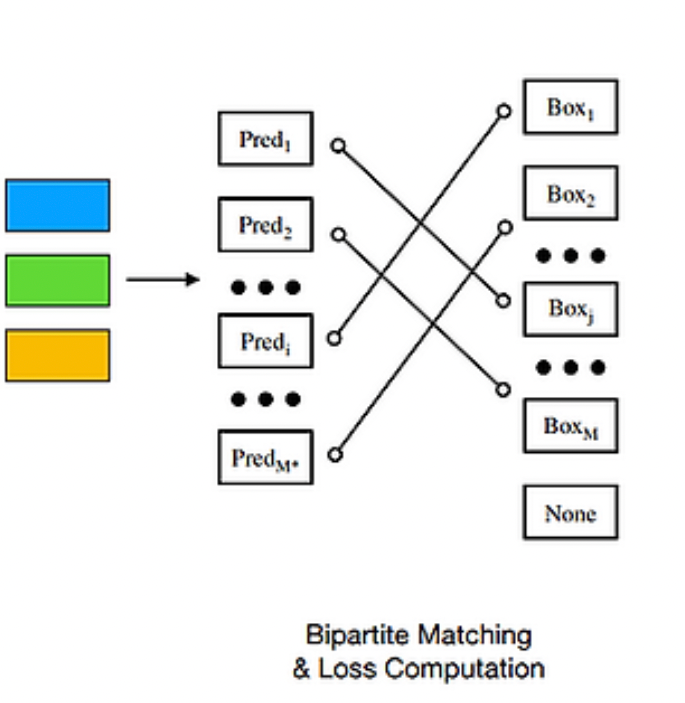
이렇게 갯수를 맞춰준 뒤 GT와 예측값 사이 Set-to-set Loss를 계산하려면 예측값과 GT 사이의 최적의 짝궁을 찾아줘야 합니다. 짝궁을 찾는 과정은 Bipartite Matching(이분 매칭)을 통해 수행되고 수식은 아래와 같습니다.
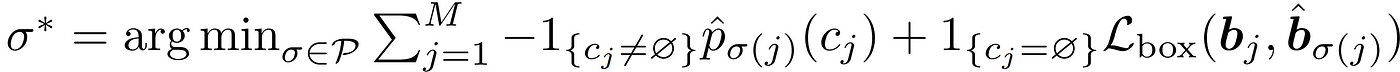
Bipartite Matching의 최종 목적은 예측값과 GT 사이의 비용이 가장 작은 짝궁을 찾아주는 것입니다. 결과적으로 수식 7을 통해 최적의 짝궁 σ*를 구하게됩니다.
이렇게 얻어진 짝꿍끼리의 Loss를 최소화 하는 방향으로 모델은 학습되게 됩니다.
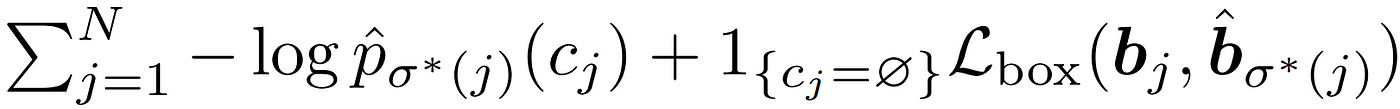
4. Experiments
4.1 Implementation Details
본 논문은 모델의 성능을 평가하기 위해 nuScenes 데이터셋을 사용합니다.
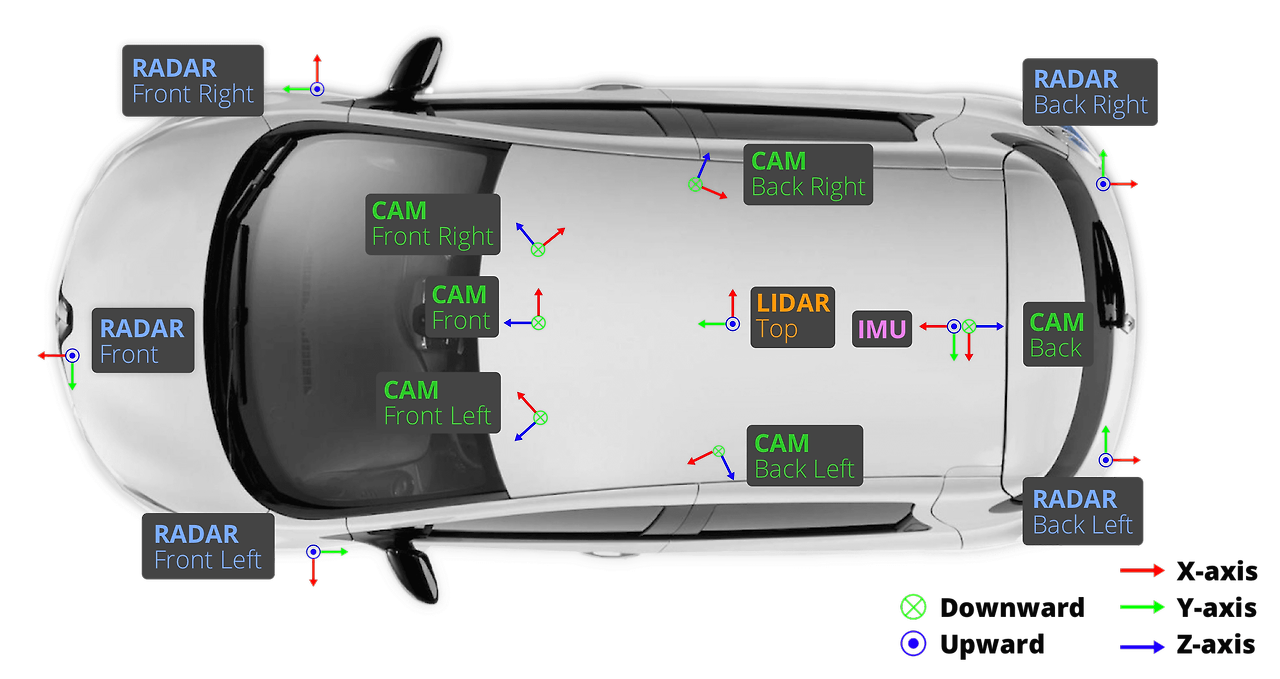
nuScenes 데이터셋은 Lidar 1개, Radar 5개, Camera 6개, IMU, GPS 로 수집된 1,400,000개의 카메라 이미지+ 1,400,000개 수작업 annotation 데이터셋입니다. (140만개를 수작업으로 3D BBox annotation 했다니 엄청나게 많은 돈과 시간이 들었을 것 같습니다... )평가지표는 다음과 같습니다.
- ATE (Average Translation Error): 평균 변환 오차
- ASE (Average Scale Error): 평균 크기 오차
- AOE (Average Orientation Error): 평균 방향 오차
- AVE (Average Velocity Error): 평균 속도 오차
- AAE (Average Attribute Error): 평균 속성 오차
- mAP (Mean Average Precision): 평균 정밀도
- NDS (nuScenes Detection Score): nuScenes 검출 점수
논문에 따르면 DETR3D 를 모델링할 때 다음과 같이 실험 세팅 후 진행했다고 합니다.
- ResNet-101을 Backbone으로 사용하였지만 3번째와 4번째 layer는 Deformable Convolution을 사용
- Neck으로 FPN을 사용하였음. 입력 이미지에 대해 1/8. 1/16, 1/32, 1/64 크기 Multi-scale Feature map 생성
(이때, Head 안의 Hidden layer 차원은 256) - DETR3D의 Head는 총 6개의 층을 갖고, 각 층은 Feature Refinement Block과 Multi-head Self-attention Block으로 구성됨
- Bounding Box와 Class Score를 예측하기 위해 Sub-network 사용. 각 Sub-network은 입력, hidden, 출력 층으로 구성됨
(이때, Hidden layer 차원은 256) - Head에서 Layer Normalization 기법 사용
4.2 Comparison to Existing Works

- mATE 측면에서 FCOS3D보다 성능이 떨어집니다. 이는 FCOS3D가 경계 상자 깊이를 직접 예측하기 때문에, 객체의 변환에 대한 강력한 감독을 제공하기 때문임
- NMS와 같은 후처리 과정 없이도 우수한 성능 보여줌
4.3 Comparison in Overlap Regions

- Multi-view camera를 사용하면 동일한 물체가 여러 사진에 겹쳐지는 부분이 생김
- 이러한 영역에서는 객체들이 잘리므로 ATE(Average Translation Error)가 높아짐
- 겹치는 영역에서 DETR3D 성능평가를 위해 FCOS3D와 비교함
- GT에서 개체의 3D BBox의 중심좌표가 여러 카메라 이미지에 속할 경우 겹치는 영역에 포함되었다고 판단
- FCOS보다 겹치는 영역에서 우수한 성능 보임
4.3 Comparison to pseudo-LiDAR Methods
- 논문에서 Pseudo-LiDAR 방식과 성능을 비교하였고 DETR3D가 훨씬 뛰어난 성능을 보여줌
5. Conclusion
Strength
- 3D 객체 쿼리 사용: 3D 객체 쿼리를 사용하여 객체의 위치, 크기, 방향 정보를 표현함으로써 3D 공간상에서 객체를 탐지할 수 있음. 이는 2D OD 결과를 통합하는 것보다 더 정확한 3D OD 결과를 얻을 수 있음
- 후처리 불필요: NMS와 같은 후처리과정이 필요하지 않아 Computation Cost가 낮음
- Depth Estimation 불필요: 별도의 Depth Estimation 과정이 필요없기 때문에, Depth Error가 3D OD 결과에 악영향을 끼치지 않음
Weakness
- 일부 측면에서 기존 방법보다 더 낮은 성능: 실험 단계에서 언급한 바와 같이 FCOS3D과 비교하여 성능이 더 낮게 나오는 경우가 발생함.
- 2D OD 모델보다 높은 계산비용: DETR3D 모델은 객체 쿼리라는 추가적인 파라미터를 도입함으로써 기존 2D OD 모델보다 높은 계산 비용이 발생함
6. Question
이태훈님 질문1. Cli 과 1을 concat함으로써 3차원을 4차원을 확장했다고 하셨는데 어떻게 확장 되는지 궁금합니다. 그리고 4차원으로 확장하는것이 3차원보다 점의 위치를 표현하는데 편리하다고 하셨는데 어떤점에서 편리한지 설명해주시면 감사하겠습니다.
답변: 기본적으로 3D 좌표는 (x,y,z) 형태입니다. 동차 좌표계에서는 이를 4D 좌표(x,y,z,w) 형태로 확장하게 됩니다. 여기서 w는 1로 설정이 된거구요. concat 한다는게 사전적으로 "연결"을 의미하는데요. 3D 참조점 cli (x,y,z)와 1을 concat 함으로써 4D 좌표(x,y,z,1)로 확장되었습니다. 이렇게 3D 참조점을 4D 좌표로 확장하여 얻게되는 계산상의 편의성은 다음과 같아요.
회전변환, 스케일링 변환 등은 모두 행렬 연산으로 계산할 수 있습니다. 그러나 이동변환의 경우 3차원 좌표계에서 행렬 연산으로 표현할 수가 없다는 문제점이 있습니다. 기왕이면 모든 변환과정이 행렬 연산으로 통일되면 계산이 편하겠죠? 그래서 이동 변환도 행렬 연산 형태로 표현하기 위해 4D 좌표계로 변환해주는 겁니다!
이태훈님 질문2. Deformable attention의 정의와 어떻게 computational cost를 줄이는지 궁금합니다.
답변: 기존 Self-Attention 과정은 모든 쿼리와 key 간의 내적을 통해 Attention Score를 계산하였습니다. 그러나 Deformable- Attention은 모든 쿼리와 key 간의 내적을 수행하는 대신 몇개의 중요한 key 위치만을 선택하여 Attention Score를 계산합니다. 일종의 가지치기라고 할 수 있습니다. 몇개의 중요한 key만 계산하기 때문에 Computation cost를 줄일 수 있습니다.
이하정님 질문1. 객체 쿼리가 어떤 형태인건지, 단순히 기존의 detection 모델을 학습하는 것(경계상자의 위치를 예측하는 것)과 어떤 점이 다른 건지 궁금합니다
답변: 객체쿼리는 일종의 학습가능한 파라미터 입니다. 이러한 객체쿼리는 학습과정에서 Detection Head의 Transformer 디코더 layer에서 초기화 및 업데이트 됩니다. 각 객체 쿼리는 잠재적인 하나의 객체의 관한 정보를 담고있으며, 각각의 쿼리는 객체의 위치, 크기, 방향, 속도를 예측합니다.
예를들어, 논문에서 객체 쿼리 개수를 900개로 지정한 경우, 이는 모델이 각 이미지에서 최대 900개의 객체를 검출할 수 있도록 설정된 것을 말합니다.
기존 객체 검출 모델과의 차이점은 yolo를 예로들어 설명해보겠습니다.
기존 객체 검출 모델
yolo 모델에서 업데이트되는 파라미터는 네트워크의 가중치(weights)와 바이어스(biases) 총 2개 입니다.
DETR3D
DETR3D에서 업데이트되는 파라미터는 네트워크의 가중치(weights)와 바이어스(biases)에 객체 쿼리(object query) 총 3개 입니다.
결론적으로 DETR3D에서 객체 쿼리는 단순하게 weight와 같이 학습과정에서 update되는 일종의 파라미터입니다
'논문 리뷰' 카테고리의 다른 글
| [논문리뷰]Integer Quantization: 모델 경량화 기본 (0) | 2024.08.21 |
|---|---|
| [논문리뷰]HDRUNet: 단일 프레임 HDR 챌린지 SOTA (0) | 2024.08.04 |
| [논문 리뷰] PointNet (CVPR 2017): point cloud를 직접 처리 (0) | 2024.06.27 |
| [논문 리뷰] NeRF (ECCV 2020): 최초의 NeRF (0) | 2024.06.18 |
| [논문리뷰] HITNet (CVPR 2023) : cost volume aggregation 속도 향상 (0) | 2024.05.31 |