목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 NVIDIA에서 2020년 4월에 발표한 INTEGER QUANTIZATION FOR DEEP LEARNING INFERENCE: PRINCIPLES AND EMPIRICAL EVALUATION 이라는 논문입니다.
제가 이 논문을 리뷰하는 이유는 최근 진행중인 "농장주를 위한 가축 성장관리 서비스"에 사용되는 Instance Segmentation 모델을 경량화하여 Inference time과 AWS Inference 요금을 절감해보고자 리뷰하게 되었습니다.
0. 모델 경량화
모델 경량화에는 크게 세 가지 방법이 존재합니다. 각각 Pruning, Quantization, Distillation인데요. 세 가지 방식 모두 큰 모델을 작게 변환하는 것은 동일하나 방식에 차이가 있습니다.
- 중요하지 않은 부분을 적절히 가지치기 할것인가 (Pruning)
- 해상도를 낮춰서 작게 만들 것인가 (Quantization)
- Teacher 모델로부터 Student 모델을 학습하여 크기 자체를 작게 만들 것인가 (Distillation)
아래 그림을 참고하시면 이해에 도움이 될 것입니다.

이 세가지 중 오늘 리뷰할 논문은 Quantization에 관한 논문입니다.
Quantization(양자화)란 float32(32-bit 부동소수점) 대신 int8(8-bit 정수)와 같은 저정밀도 데이터 유형으로 가중치와 활성화를 표현하여 추론을 실행하는데 드는 cost와 memory를 줄이는 기술입니다. 이론적으로 float32->int8로 데이터 유형을 변경하면 모델 크기가 1/4배 되는 효과를 얻을 수 있습니다(심지어 최근에는 int2 까지 줄이는 연구가 진행되었습니다). 하지만 고정밀 데이터 유형에서 저정밀 데이터 유형으로 변환하는 과정에서 계산 및 메모리상의 이득을 보는만큼 정확도에서 손해를 입게됩니다. 그러므로 계산 및 메모리와 모델 정확도는 trade-off 관계에 있다고 할 수 있습니다.
1. Introduction
기존 신경망 훈련은 float32(32-bit 부동소수점) 형식을 주로 사용했으나, 최근에는 IEEE fp16 혹은 bfloat16과 같은 16비트 부동소수점 형식으로 신경망을 훈련시키는 다양한 연구가 진행되었습니다. 그렇다면 굳이 왜 이렇게 더 낮은 정밀도로 데이터를 변환하는 걸까요? 더 낮은 정밀도(낮은 비트) 형식을 사용하면 꽤 다양한 이점이 있습니다.
- 프로세서가 같은 시간에 더 많은 계산을 처리할 수 있도록 합니다.
- 메모리 대역폭 부담을 줄여 대역폭에 제한이 있는 계산의 성능을 향상시킵니다.
- 메모리 크기 요구사항을 줄여 캐시 활용도 및 메모리 시스템 작동을 개선시킵니다.

위 표를 보면 INT8 형식을 사용했을 때, 기존 FP32보다 최대 16배의 계산속도 향상을 보이는 것을 확인할 수 있습니다. 또한 메모리 대역폭에 의해 성능이 제한되는 경우 INT8 형식을 사용하면 기존대비 4배의 계산속도 향상을 보였습니다.
메모리 대역폭에 의해 성능이 제한되는 경우?
: 메모리 대역폭(메모리로부터 데이터를 읽고 쓰는 속도)에 의해 성능이 제한되는 경우를 말합니다. 이런 경우 CPU나 GPU와 같은 프로세서의 성능은 충분하지만, 메모리에서 데이터를 가져오고 저장하는 속도가 느려서 전체 성능이 느려지는 경우를 말합니다.
예를들어, 딥러닝 모델에서 대규모 데이터(이미지 or 텍스트)를 처리할 때, 데이터가 메모리에서 프로세서로 전달되는 속도가 느려서 계산속도가 느려질 수 있습니다. 이러한 상황에서 낮은 정밀도(낮은 비트) 형식을 사용하면 데이터의 크기를 줄일 수 있기 때문에 결과적으로 메모리 대역폭에 제한이 있는 연산의 성능이 개선됩니다!
출처: https://users.ece.cmu.edu/~koopman/stack_computers/sec9_4.html
2. Related Work
이 부분에서는 균일, 비균일 Quantization 등 기존의 다양한 양자화 기법들을 소개합니다.
(궁금하신분들은 논문을 참고하시면 좋을 것 같습니다.)
3. Quantization Fundamentals
본 논문에서는 높은 처리량의 integer math pipelines을 사용할 수 있게 해주는 uniform quantization에 대해 중점을 둡니다. uniform quantization은 크게 두 단계로 나눌 수 있습니다.
- 양자화할 실수 범위를 선택하고, 이 범위를 벗어난 값을 클리핑(잘라내기)
- 양자화된 표현으로 표현 가능한 비트폭에 맞춰서 실제값을 정수로 매핑(매핑된 실제값은 가장 가까운 정수값으로 반올림)
예를들어, float32의 값의 범위가 (-3.4 x 10^38 ~ 3.4 x 10^38) 이고, INT8의 값의 범위가 (-128 ~ 127)이므로
단순하게 float32로 표현된 -75000이라는 값을 INT8로 변환하면서 -128로 클리핑될까요? 아닙니다! 본 논문에서는 이 실수 범위를 선택하기 위해 3가지 보정방법을 사용했습니다. 이는 뒤에 나오는 3.4 calibration 파트에서 자세히 설명하도록 하겠습니다 :)
여기서는 그냥 이런 순서로 양자화가 진행되었구나~ 정도만 이해하고 넘어가겠습니다.
3.1 Range Mapping
양자화할 실수 표현의 범위가 [β,α]이고, b를 부호있는 정수 표현의 비트범위라고 해보겠습니다.
uniform quantization은 입력값 x ∈ [β, α] 를 [-2b-1,2b-1-1]로 변환하고, 범위를 벗어나는 입력값은 가장 가까운 경계값으로 클리핑합니다. 논문에서는 uniform transform만 다루기 때문에 두가지 변환방법만 고려합니다.
(간단하거나 굳이 필요없는 수식은 최대한 배제하겠습니다.)
- affine transformation: f(x)=s⋅x+z
- scale transformation: f(x)=s⋅x (affine의 special case)
3.1.1 Affine Quantization

이 방법은 간단하게 말하면, float32 전체 범위에서 특정 범위를 잘라낸 뒤 나머지 값만 매핑하는 방법입니다.
예를들어 float32로 학습한 모델의 weight 값이 그림과 같이 [-3, 4] 범위에 존재한다면, -3부터 0까지는 0으로 클리핑하고 0에서 4까지의 값만 int8의 [0, 255] 범위로 매핑합니다.
3.1.2 Scale Quantization

이 방법은 간단하게 말하면, float32 범위 전체를 int8 범위로 선형적으로 매핑하는 방법입니다.
예를들어 float32로 학습한 모델의 weight 값이 [-10, 30] 범위에 존재한다면 -10을 int8의 최소값인 0에, 30은 int8의 최대값인 255에 대응시킵니다. (흔히 쓰이는 normalization 과정과 동일합니다.)
3.2 Tensor Quantization Granularity
텐서 요소들 간의 quantization parameter들을 공유하는 여러가지 방법이 존재합니다. 이러한 방법들을 quantization granularity(양자화 세분화) 라고 부릅니다. 가장 러프한 수준인 "per-tensor granularity"에서는 텐서의 모든 요소가 동일한 양자화 파라미터를 공유합니다. 그리고 중간 수준인 "per-column granularity"에서는 텐서의 각 차원별로 파라미터를 공유합니다. 마지막으로 가장 미세한 수준인 "per-element granularity"에서는 개별 요소별로 각각의 양자화 파라미터를 갖습니다.
이 논문에서는 모델의 정확도와 계산 비용이라는 두가지 측면을 고려하고 있고, 최고의 성능을 뽑아내기 위해 다음과 같은 방법을 제안하고 있습니다.
- Activations: per-tensor granularity (논문에서 성능 이슈로 오직 per-tensor만 practical 하다고 언급)
- weights: per-tensor or per-column granularity
3.3 Computational Cost of Affine Quantization
앞서 아핀 양자화(Affine quantization)과 스케일 양자화(scale quantization) 모두 integer 연산을 가능하게 했지만, 아핀 양자화는 s스케일 양자화보다 더 높은 계산 비용을 유발합니다. 스케일 양자화는 정수 행렬 곱셈과 그에 따른 부동소수점 포인트별 곱셈을 합니다.
딥러닝 모델에서 dot product는 수백~수천 개의 곱셈-덧셈 연산으로 구성되기 때문에 최종적으로 단일 부동소수점 연산을 수행하는 것은 계산비용이 크지 않습니다. 반면, 아핀 양자화는 아래와 같이 계산식이 매우 복잡합니다.

이 계산은 크게 세개의 항으로 나뉩니다.
- 첫 번째 항은 스케일 양자화와 동일한 정수 dot product 항입니다.
- 두 번째 항은 integer weights와 zero-point로만 구성된 항입니다.
(결과적으로 첫번째, 두번째 항은 아핀에서 계산될 수 있는 부분이고, 추론에서 element-wise addition만 추가하면 됩니다.) - 세 번째 항은 양자화된 입력 xq가 포함되어 있으므로 아핀으로 계산할 수 없습니다. 구현 방식에 따라 이 연산에는 상당한 오버헤드가 발생할 수 있습니다.
이 연산은 아핀 양자화를 사용할 때만 발생하므로, 추론 성능을 최대화하려면 scale quantization이 더 유리합니다. 이 논문에서는 scale quantization으로 충분한 정확도를 얻을 수 있다고 언급합니다.
3.4 Calibration
앞서 uniform quantization은 가장 먼저 "양자화할 텐서의 범위를 선택"해야 한다고 했습니다. 이러한 범위 선택 과정을 calibration(보정)이라고 부릅니다. 이러한 보정 과정은 주어진 데이터셋의 대표 샘플을 기반으로 수행됩니다.
- 최대값 보정(max calibration): 이 방법은 데이터의 모든 값을 포함할 수 있도록 최대 절대값을 찾습니다. 이 최대 절대값을 기준으로 스케일 팩터를 결정합니다. 이 방식은 가장 간단하지만, 이상치에 취약합니다.
- 엔트로피 보정(entropy calibration): 이 방법은 KL 발산(Kullback-Leibler divergence) 최소화를 통해 원래의 분포와 양자화된 분포 간의 정보 손실을 최소화하는 방법입니다. 대표적으로 TensorRT의 보정과정에서 기본값으로 사용됩니다.
- 백분위수 보정(percentile calibration): 이 방법은 특정 백분위수(ex: 99.9%)에 해당하는 값을 기준으로 스케일링 팩터를 결정합니다. 예를들어, 데이터의 상위 0.1%의 값이 클리핑 되더라도 나머지 값들이 더 정확하게 표현되도록 하는 방식입니다.
이 논문에서는 이러한 다양한 보정 방법을 사용해서 양자화된 모델의 성능을 평가했습니다.
4. Post Training Quantization
PTQ(Post Training Quantization)는 모델이 훈련을 마친 뒤, 별도의 재훈련 과정 없이 양자화하는 방법입니다.
사실 학습과정에서 quantization을 적용하려면 코드를 수정하는데 많은 시간과 노력이 필요합니다. 그래서 저같은 경우 가장 간단하게 모델을 경량화할 수 있는 PTQ를 선호합니다.
이 섹션에서는 다양한 네트워크 아키텍처에 PTQ를 적용하고 결과를 비교합니다.
실험조건은 다음과 같습니다.
- weights와 activation을 8bit quantization을 중심으로 PTQ 진행
- 앞서 3장에서 논의한 다양한 calibration 기법을 사용해서 최적의 scale factor와 zero-point 설정
4.1 Weight Quantization

ResNet-50, Inception-v3, MobileNet-v2 등 다양한 이미지 분류 네트워크에 PTQ를 적용하고 모델 정확도를 비교하였습니다.
실험결과 표 3과 같이 대부분 PTQ 후에도 quantization 이전 모델과 유사한 정확도를 보였습니다. 특히 ResNet-50 모델은 정확도가 1% 미만 감소하였습니다. 반면 MobileNet-v2는 상대적으로 양자화에 더 민감했고, 이는 이 네트워크가 보다 복잡한 비선형성을 갖고 있기 때문이라고 언급합니다.
(여기서 주목할점!: 비선형성이 큰 모델을 압축하면 정확도 손실이 크다!!)
복잡한 비선형성?
: 딥러닝 네트워크에서 비선형성은 주로 활성화 함수와 같은 요소들로 인해 발생합니다. 활성화 함수는 뉴럴 네트워크의 각 레이어가 단순한 선형 변환만 수행하지 않도록 해서 네트워크가 복잡한 패턴과 비 선형적인 관계를 학습할 수 있도록 합니다.
4.2 Activation Quantization
활성화 양자화는 네트워크의 가중치 양자화보다 더 어려운 문제입니다. 그 이유는 활성화 값이 입력 데이터에 따라 다르게 분포하기 때문입니다. 또한 특정 입력에 대한 활성화 값의 범위는 매우 넓을 수 있고, 이러한 값의 범위는 네트워크에서 레이어마다 다를 수 있습니다.
그렇다면 이러한 activation들의 양자화는 어떻게 진행될까요?
아래 표는 다양한 네트워크 아키텍처에 activation quantization을 적용하고 다양한 calibaration 방법(max, entropy, percentile)에 따라 결과가 어떻게 달라지는지 보여주는 실험결과입니다.
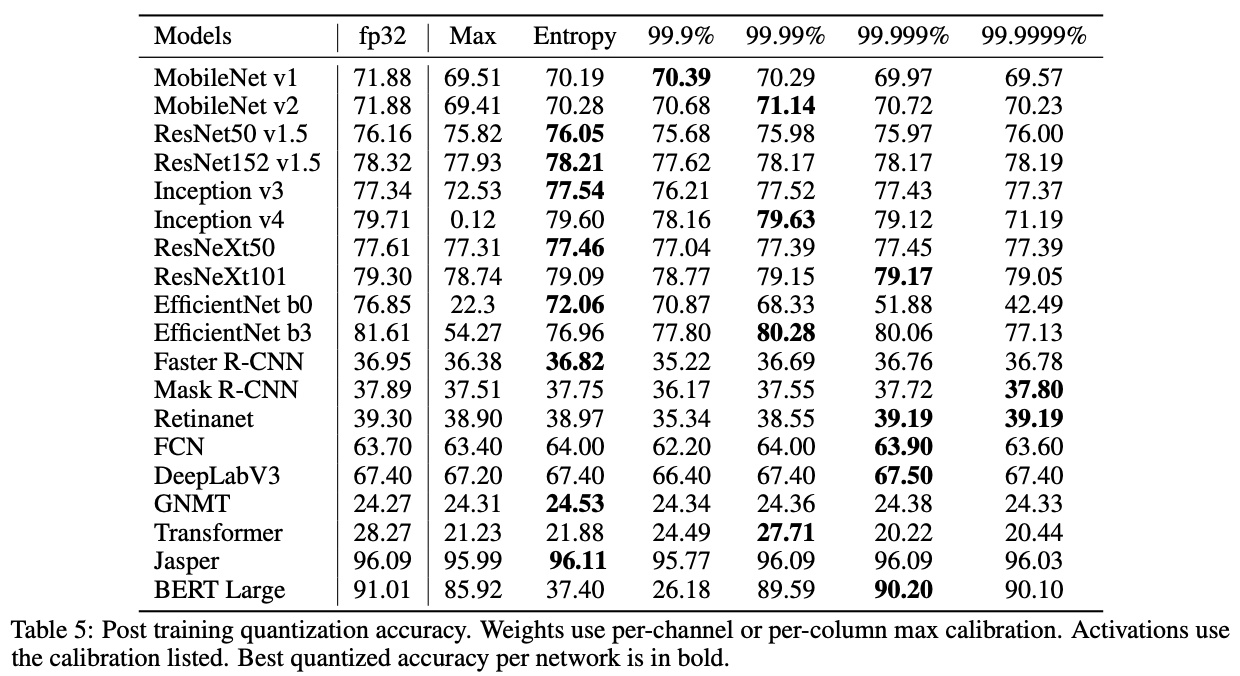
대부분의 네트워크에서 허용 가능한 정확도를 달성하는 activation quantization 방법(max, entropy, percentile)이 적어도 하나는 존재했습니다.
5. Techniques to Recover Accuracy
네트워크 학습 이후 PTQ를 적용했을 때, 정확도가 많이 떨어지는 경우가 종종 발생합니다. 저자들은 이렇게 떨어진 정확도를 복구하는 방법을 친절하게 설명해줍니다.
5.1 Partial Quantization
이 방법은 양자화에 민감한 layer는 양자화에서 제외하는 방법입니다.
그렇다면 이런 민감한 layer는 어떻게 찾을까요? 본 논문에서는 one-at-a-time sensitivity analysis를 제안합니다.
one-at-a-time sensitivity analysis란 한 번에 한 레이어씩 양자화를 수행하고 정확도를 평가하는 방식을 말합니다.

위 그래프는 EfficientNet b0의 sensitivity analysis와 partial quantization 결과를 보여주는데요.
결과적으로 양자화에 가장 민감했던 10개의 레이어를 찾고 이러한 민감 레이어들은 양자화에서 제외하고 나머지만 양자화를 진행한다면 정확도를 끌어올릴 수 있다고 합니다.
5.2 Quantization-Aware Training
이 방법은 네트워크를 학습할 때 or fine-tuning 전에 양자화를 네트워크에 추가하는 방법입니다.
여기서 저자는 QAT(Quantization Aware Traing)가 PTQ보다 모델 정확도가 더 높다고 언급합니다.
그 이유는 아래 그림과 같이 PTQ는 에서 local minimum으로 수렴했고, scale factor가 1인 경우 weight가 가장 가까운 정수 wq = -1로 양자화되기 때문에 매우 큰 loss를 유발하기 때문입니다.
반면에 QAT는 양자화된 weights에 대한 기울기를 계산해서 narrow minimum을 잠재적으로 피할 수 있습니다. 이를 통해 잠재적으로 모델이 잠재적으로 'wide' or 'flat' minimum에 대한 loss를 탐색할 수 있도록 합니다. 따라서 loss가 더 낮고 정확도는 높아지게 됩니다..

아래 표를 살펴보면 PTQ 방법과 QAT 방법의 모델 정확도를 한눈에 비교할 수 있습니다.

전반적으로 QAT 방식이 모델 정확도가 더 높습니다...!
5.3 Learning Quantization Parameters
이 방법은 model weights와 quantization parameters(sscale factor, zero-point 등)를 함께 학습하는 방법입니다.
앞선 방법들은 scale factor와 zero-point를 직접 설정해주는 방법이였다면, 이 방법은 이것들 마저 하나의 파라미터로 만들어서 모델이 학습할 수 있도록 하는 방법입니다.

표를 살펴보면, activation 양자화가 max calibration으로 초기화될 때, 대부분의 네트워크에서 범위를 학습하는 것이 고정된 상태로 유지하는 것보다 더 높은 정확도를 보였습니다. 특히, 고정된 max 범위가 상당한 정확도 저하를 초래한 경우(Inception v4)에 큰 정확도 개선을 가져옵니다.
6. Recommended Workflow
위 결과를 바탕으로 본 논문에서는 다음을 만족하는 INT8 quantization을 권장합니다.
weights
- Use scale quantization with per-column/per-channel granularity
- Use a symmetric integer range for quantization [-127, 127] and max calibration
Activations
- Use scale quantization per-tensor granularity
또한 이미 학습된 네트워크를 양자화하기 위해 추천하는 절차는 다음과 같습니다.

- PTQ: 모든 computationally intensive layers (conv, linear, matmul...)를 양자화하고, max/entropy/percentile을 포함하는 activation calibration을 수행한다. 원하는 성능을 얻지 못한경우 partial quantization or QAT를 사용해라.
- Partial Quantization: Sensitivity analysis를 통해 양자화에 민감한 layer를 찾고, 이러한 레이어들은 양자화하지 않는다. 그래도 성능을 만족하지 못하면 QAT를 사용해라.
- QAT: 가장 calibration이 잘 된 quantized model로부터 ㅣ작한다. 본래 학습에 사용했던 스케쥴의 10% 정도만 사용하여 fine-tuning을 수행하고, 초기 training learning rate의 1%만 사용한다.
7. Conclusions
이 논문은 모델의 정확도 손실 없이 효과적으로 양자화하는 "꿀팁"을 실험을 통해 알려주는 아주 고마운 논문이었습니다.
제가 정리한 quantization 꿀팁은 다음과 같습니다.
- 비선형성이 큰 모델을 양자화하면 정확도 손실이 크다! 따라서 사용하는 모델에 활성화 함수 layer가 많으면 많을수록 비선형적인 모델이고, 이러한 모델들을 양자화하면 결과적으로 정확도 손실이 클 것이다!
- 모든 네트워크에서 최선의 calibration 방법은 없다. 즉, 본인의 네트워크를 양자화할 때 다양한 calibration 기법들을 적용해보고 모델 정확도를 비교해서 자신의 모델에 적합한 방법을 찾아야한다!
- QAT가 PTQ보다 모델 정확도 손실이 적다!
우리가 모델을 경량화할 때 단순히 pytorch model을 onnx로 바꾸고 float32 형식을 INT8 형식으로 바꾸는게 아니라 모델 정확도를 최대한 살리면서 경량화 하는게 정말 모델 경량화를 제대로! 하는 방법이라고 생각합니다. 이 논문을 통해 어떻게 하면 모델 정확도 손실을 최소화할 수 있는지에 대한 많은 인사이트를 얻은 것 같아서 제 주변 분들에게도 꼭 추천드리고 싶은 논문이었습니다 :)
'논문 리뷰' 카테고리의 다른 글
| [논문리뷰]RawHDR: Raw 데이터로부터 HDR 이미지 복원하기 (4) | 2024.09.25 |
|---|---|
| [논문리뷰]Replacing Mobile Camera ISP: 딥러닝으로 ISP 대체하기 (0) | 2024.09.05 |
| [논문리뷰]HDRUNet: 단일 프레임 HDR 챌린지 SOTA (0) | 2024.08.04 |
| [논문리뷰] DETR3D (CoRL 2022): multi-view 이미지를 이용한 3D OD (3) | 2024.07.24 |
| [논문 리뷰] PointNet (CVPR 2017): point cloud를 직접 처리 (0) | 2024.06.27 |