목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 일명 NeRF입니다. NeRF는 단순히 이미지만으로 객체의 3D model을 생성하는 기술이 아닌, 특정 3D 장면을 여러 각도에서 바라본 이미지가 제공되면 이미지가 제공되지 않았던 시점에서 바라본 scene을 생성하는 Novel View Synthesis 기술입니다. 논문 소개에 앞서 본 논문을 이해하는데 필요한 최소한의 배경지식부터 소개해보도록 하겠습니다.
1. Background
지금까지 특정 몇개의 시점과 방향에서 촬영한 이미지와 카메라 파라미터 정보로 주어지지 않은 새로운 시점과 방향에서 바라본 scene의 모습을 continious하게 합성하기 위해 다양한 시도들이 이루어져 왔습니다.
1.1 3D Aware Model



- 어떤 하나의 feature(예를들어 입)를 수정하고 싶을 때, 입에 해당하는 latent vector를 찾고 latent vector를 수정함으로써 입에 해당하는 feature를 바꿈
- 생성된 이미지에서 얼룩(blob)같은 noise가 발생되거나 치아나 눈 등이 특정위치를 벗어나지 못하는 문제점이 있었음

- StyleGAN에서 아이디어를 착안하여 공간적인 정보까지 Editing 하려고 시도한 논문임
- 로테이션 정보를 어느정도 잘 학습되었지만 가장 왼쪽 사진과 가장 오른쪽 사진을 비교했을 때 다른사람처럼 보이는 문제점이 있었음(disentangle되지 않았음)
- 원하는 feature만 변화시켜야 했지만 다른 feature까지 모두 변화되버리는 한계점을 보였음
1.2 Computer Graphics
Computer Graphics는 3D 도메인에서 이미지를 어떻게 합성하거나 조작하는 연구분야입니다. 이 분야는 Task에 따라 다시 2가지 분야로 나눌 수 있습니다.

- 첫째, 다양한 방향에서 촬영한 2D 이미지를 합성하여 3D volume을 획득하는 분야(Voxel Representation)입니다. 이 분야는 점으로 표현하는 Point Cloud나 면으로 표현하는 Mesh 보다 훨씬 더 정확하다는 장점이 있지만, 모든 데이터를 큐빅 데이터로 표현하다보니 높은 computation cost가 발생하였습니다.
- 둘째, 3D 모델로부터 2D 이미지를 생성하는 분야(3D Rendering)입니다. 이 분야는 수학적 방법으로 3D 정보를 2D로 투영하는 Rendering equation을 사용함. Volume based rendering(MRI, CT) 방식과 Surface based rendering이 있습니다.
- 이는 효율적으로 어떤 함수에 최적화시키기 위해 INR(Implicit Neural Representation)이라는 기법을 사용합니다.
- INR(Implicit Neural Representation)이란 discrete data(이산적인 데이터)를 활용하여 continuous(연속적인) 함수에 optimizing하는 과정을 말합니다.
- 예를들어, UNet은 입력으로 (H x W x C)이 들어오고 출력으로 (H' x W' x C)이 나오다 보니 어떤 discrete한 data가 들어왔을 때는 그에 해당하는 RGB 값을 알 수 있지만, continious한 data가 들어왔을 때는 그에 해당하는 RGB값을 알 수 없습니다.이러한 문제를 해결하기 위해 임의의 x,y 좌표가 들어왔을 때 그에 해당하는 RGB 값을 출력으로 하는 하나의 함수를 정의하고 그 함수를 최적화시키는 일종의 회귀모델을 통해 continious한 data가 들어오더라도 그에 해당하는 RGB값을 회귀 할 수 있게 되었습니다. 그래서 INR 모델은 임의의 연속적인 x,y 좌표가 입력으로 들어오더라도 그에 해당하는 RGB값을 얻을 수 있습니다.

- INR은 low resolution으로 학습을 시키더라도 high resolution의 데이터를 얻을 수 있습니다. 또한 원래 discrete한 곳에서는 미분값을 계산할 때 근사값을 구할 수 밖에 없지만, INR을 사용하여 continious해진 경우에는 미분값을 직접적으로 구할 수 있다는 장점이 있습니다.
- 또한 discrete한 모델같은 경우 픽셀단위의 probability를 다 구해야 되기 때문에 모델의 복잡도가 픽셀의 resolution에 비례하여 커지지만 INR같은 경우에는 픽셀에 대한 학습이 빠졌기 때문에 모델의 복잡도가 데이터의 복잡도에 비례하여 커지게 됩니다. 결과적으로 일반적인 discrete 모델보다 매우 가벼운 모델을 얻을 수 있습니다.
2. Introduction
2.1 새로운 방식 제안
- 오랜 골칫거리였던 Novel View Synthesis 문제를 해결하기 위해 5D scene representation 매개변수를 직접 최적화하는 새로운 방식을 제안함
- 본 논문에서 저자는 5차원 데이터(x, y, z, θ, φ)를 입력받아 해당 시점에서 물체를 바라봤을 때, 물체로부터 Radiance(r,g,b)와 Density(σ)를 추출하는 함수를 사용함
- Radiance는 3D 월드좌표계에서 ray상의 위치한 3D point의 좌표(x,y,z)에서 (θ, φ) 방향으로 방출되는 광원(r,g,b)을 말하고, Density는 (x,y,z)를 지나는 가상의 레이저(시점을 벡터로 표현한 것)에 축적되는 물질의 밀도(σ) 즉, 그 좌표에서 빛이 흡수되거나 산란되는 정도를 말함
- 저자는 5차원 데이터(x, y, z, θ, φ)로부터 Radiance(r,g,b)와 Density(σ)를 회귀하기 위해 MLP를 사용함
- 그리고 classical volume rendering techniques를 이용하여 MLP로 얻은 (r,g,b,σ) 데이터들을 2차원 이미지에 투영하여 결과적으로 특정 시점에서 바라본 물체의 scene을 얻습니다.
- 저자는 이러한 일련의 과정을 neural radiance field(NeRF)라고 이름지었음

- NeRF를 수행하는 과정(앞선 과정)을 정리하면 다음과 같습니다.
1. 카메라의 위치와 방향이 결정되면, 카메라에서 물체를 향하도록 ray를 투사하고 ray 상의 존재하는 무한한 포인트중에서 near bound~far bound 사이의 3D 포인트(x,y,z)들을 균일한 간격으로 샘플링
2. 샘플링된 3D 포인트들의 5차원 좌표(x,y,z,θ, φ)를 MLP(𝐹𝜃)에 입력하여 모든 포인트들의 RGB값(r,g,b)과 밀도(σ) 반환
(x,y,z,θ,φ) -> (r,g,b,σ)
3. classical volume rendering techniques를 사용하여 이러한 색상(r,g,b)과 볼륨밀도(σ)를 2D 이미지에 투영
(=하나의 픽셀값으로 만들어줌->이미지 픽셀값 획득-> pred image 획득)
4. 추론된 이미지(pred image)와 해당 지점에서 실제로 관측된 이미지(GT image)의 L2 loss를 계산하여 loss값 계산
(loss값이 작아지도록 MLP 학습!) - 저자는 NeRF를 수행하는 과정이 미분 가능하기 때문에, 해당 지점에서 실제로 관측된 이미지(GT image)와 MLP+classical volume rendering techniques로 만들어진 이미지(Pred image) 사이의 에러를 계산해 경사하강법으로 MLP를 최적화 시킬 수 있다고 설명함.
ray 상에 존재하는 point들은 이론적으로 무한대인데 어떤 기준으로 점을 샘플링하는건지?
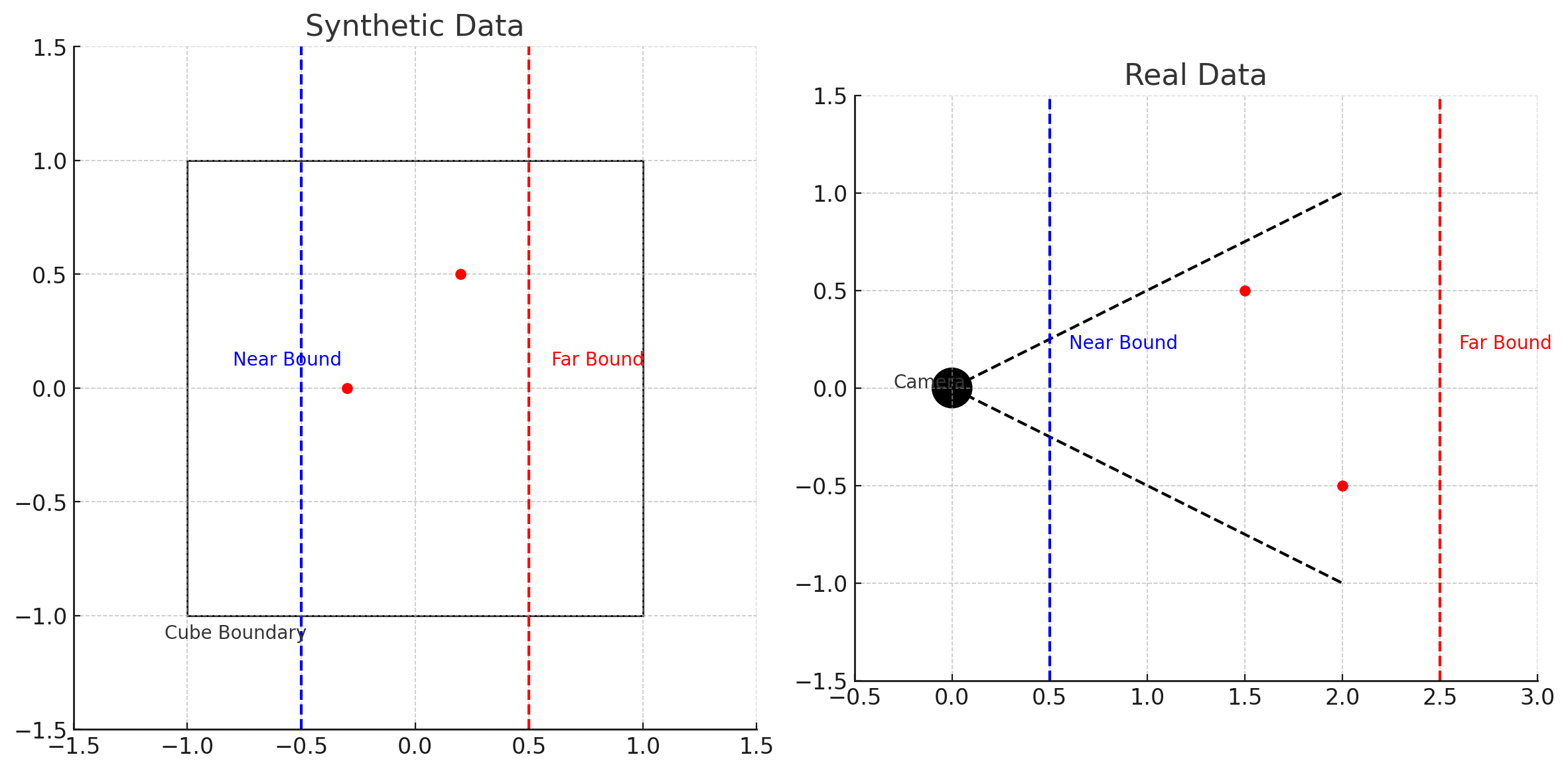
: 본 논문에서 저자는 ray상에 존재하는 무한한 점들을 near bound~far bound 범위로 제한하여 그 안에 있는 점들을 샘플링 하였습니다. near bound와 far bound를 결정하는 방법은 아래 그림과 같이 2가지 경우로 나눠서 결정할 수 있습니다.
- 첫째, 합성 데이터의 경우 우리는 이미 장면의 경계를 명확히 알고 있으므로, 장면을 감싸는 최소한의 경계 상자를 정의할 수 있습니다. 예를 들어, 장면이 중심이 원점이고 크기가 2인 큐브 안에 들어있다고 가정하면, near bound는 -1, far bound는 1로 설정될 수 있습니다.
- 둘째 실제 데이터의 경우 우리는 장면의 경계가 어디인지 알지 못합니다. 그래서 일반적으로 camera pose와 카메라로부터 피사체까지의 거리에 따라 near bound와 far bound를 설정합니다. 예를들어, 피사체가 카메라로부터 평균적으로 1m에서 5m 사이에 있다고 가정하면, near bound는 0.5m, far bound는 6m로 설정하여 모든 피사체를 샘플링 할 수 있도록 합니다.)
2.2 복잡한 scene 표현을 위한 문제점 보완
- 본 논문에서 저자는 NeRF를 최적화하는 basic implementation이 복잡한 scene에서 충분히 높은 해상도를 표현하지 못하며 카메라 ray 당 필요한 샘플 수가 비효율적이라는 것을 발견함
- 그래서 두가지 기법을 도입하여 높은 해상도를 표현하지 못하는 문제, 카메라 ray당 필요한 샘플 수가 비효율적인 문제를 해결함.
- 첫번째, 높은 해상도를 표현하지 못하는 문제는 5D 입력값(x,y,z,θ,φ)를 positional encoding으로 변환함으로써 high frequency scene content를 표현할 수 있게 함
high frequency scene context를 표현할 수 있게됨?
: 경계선을 표현하는 능력이 더 좋아짐을 말합니다. 이미지의 low frequency scene context는 배경과 같이 rgb값의 변화가 적은 곳을 뜻하고, high frequency scene context는 경계선과 같이 rgb 값의 변동이 큰 지역을 뜻합니다.
- 두번째, 카메라 ray당 필요한 샘플 수가 비효율적인 문제는 hierarchical sampling 방식을 적용하여 요구되는 쿼리의 숫자를 감소시키고, high frequency scene context를 표현할 때 필요한 sampled set의 개수를 줄여주었습니다. 결론적으로 volume rendering의 고질적인 문제인 높은 computation cost를 해결하였습니다.
3. Related Work
이전에는 도대체 어떤 문제가 있었길래 저자가 이러한 문제를 해결하려 하였는지 이해하기 위해 기존에 진행된 연구를 살펴보겠습니다.
컴퓨터 비전 분야에서 이때 당시 주목받던 연구방향은 다음과 같습니다.
- 연구방향: MLP의 가중치에 객체와 장면을 인코딩하여 2D(x,y) 좌표를 3D(x,y,z) 좌표로 직접 매핑
- Limitation: 복잡한 형상이 들어왔을 때 삼각형 메쉬나 복셀 그리드와 같이 이산 표현을 사용하는 기술보다 정확도가 떨어짐
이러한 문제점을 해결하기 위해 2D 이미지를 3D로 표현하는 Neural 3D shape representation과 3D 정보가 들어왔을 때 2D로 투영시키는 View synthesis and image-based rendering 이라는 방법이 제안되었습니다.
3.1 Neural 3D shape representation(2D to 3D)
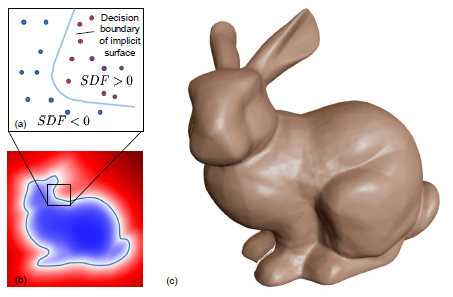
기존 연구
- (x,y,z) 좌표를 바탕으로 그림과 같이 주어진 점이 어떤 표면에서 얼만큼 떨어져있는지, 표면의 안쪽에 있는지 바깥쪽에 있는지 나타내는 signed distance function을 만들어서 0보다 작을때는 물체 내부에 있고, 0보다 클때는 물체 외부에 있도록 하는 모델을 개발
- Limits
1. 배경이 깔끔한 물체만 있는 데이터여야만 하기 때문에 합성 데이터를 만들 수밖에 없었고 다양한 실험에 진행하는데 한계가 있음
최근 연구
- INR(Implicit Neural Representation)을 활용하여 2D 이미지만 학습하여 3D 표면을 표현함
1. 3D occupancy field: 수치적 방법을 사용하여 각 광선의 표면 교차점을 찾아서 2D로 투영
2. RNN을 사용하여 미분가능한 렌더링 함수 구현 - Limits
1. 3D occupancy field의 경우 표면에 다양한 광선이 들어왔을 때 local minima에 빠질 가능성이 있음
2. 미분 가능한 렌더링 함수의 경우 오버 스무딩 문제 발생 가능성이 있음
3.2 View synthesis and image-based rendering(3D to 2D)
surface-based rendering
- surface에 대한 3D 정보가 들어왔을 때 이 부분을 2D로 투영하는 방식(3D mesh -> 2D image)
- Limits
1. 성공적으로 학습을 완료하더라도 새로운 방향에 대해서 투영시키고 싶을 때 제대로 안됨(local minima, poor conditioning of the loss landscape 때문)
2. 고정된 토폴로지(위상구조)를 가진 템플릿 메쉬가 학습에 필요하기 때문에 실제 세계 장면 학습 불가능
volume-based rendering
- surface-based rendering의 문제점들을 해결하고자 새롭게 제안됨.
- 3D 정보를 2D로 투영하는데에 있어서 큰 성능향상을 이끎
- Limits
1. 모든 픽셀값을 계산하기 때문에 time complexity, space complexity가 큼
정리하자면, 본 논문이 나오기 전까지 High frequency나 High resolution을 표현할 수 있는 모델이 필요했고, real world scene에서도 학습이 가능한 모델, 마지막으로 time complexity나 space complexity가 작은 모델이 간절하게 필요한 상황이었습니다.
4. Neural Radiance Field Scene Representation
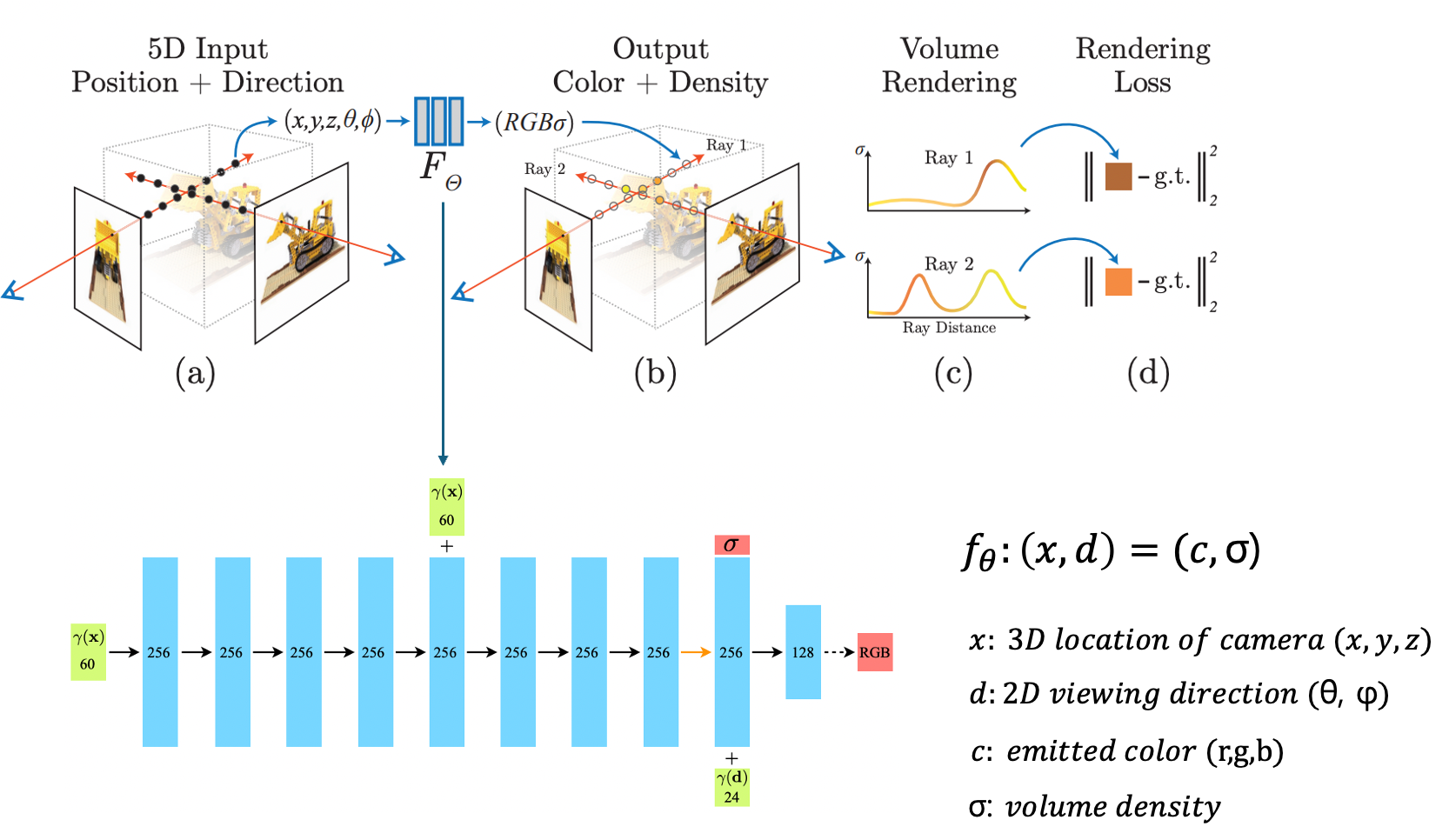
위 그림은 앞서 설명했던 NeRF의 overview입니다. Itroduction에서 살펴본 내용이지만 다시한번 순서대로 살펴보겠습니다.
1. 카메라의 위치와 방향이 결정되면, 카메라에서 물체를 향하도록 ray를 투사하고 ray 상의 존재하는 무한한 포인트중에서 near bound~far bound 사이의 3D 포인트(x,y,z)들을 균일한 간격으로 샘플링
2. 샘플링된 3D 포인트들의 5차원 좌표(x,y,z,θ, φ)를 MLP(𝐹𝜃)에 입력하여 모든 포인트들의 RGB값(r,g,b)과 밀도(σ) 반환
(x,y,z,θ,φ) -> (r,g,b,σ)
3. classical volume rendering techniques를 사용하여 이러한 색상(r,g,b)과 볼륨밀도(σ)를 2D 이미지에 투영
(=하나의 픽셀값으로 만들어줌->이미지 픽셀값 획득-> pred image 획득)
4. 추론된 이미지(pred image)와 해당 지점에서 실제로 관측된 이미지(GT image)의 L2 loss를 계산하여 loss값 계산
(loss값이 작아지도록 MLP 학습!)
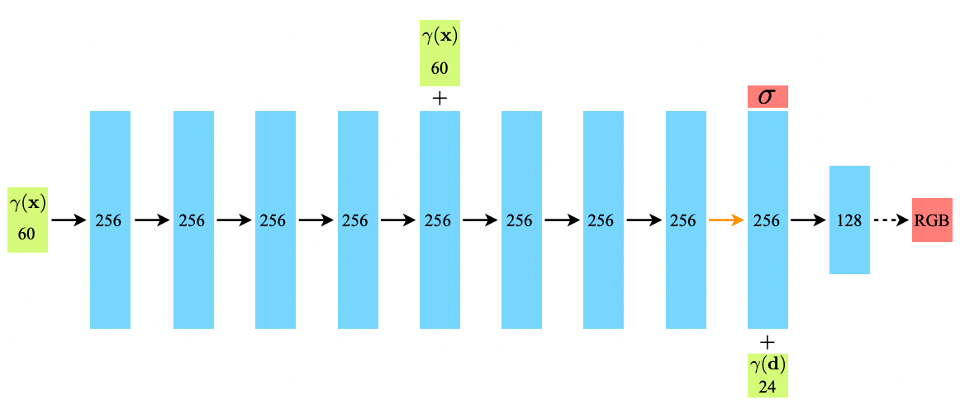
더 자세히 들어가서 MLP(𝐹𝜃) 모델의 동작과정을 살펴보겠습니다.
- 𝐹𝜃는 먼저 포인트의 3D 위치좌표(x,y,z)를 8개의 FC layer에 통과시켜 결과적으로 volume density(σ)와 256 차원의 특징벡터를 획득
- 256차원의 특징 벡터에 아까 사용하지 않았던 direction 정보(θ,φ)를 붙여서 1개의 FC layer를 통과시켜 128차원의 RGB값을 획득
저자는 density는 포인트의 3D 위치에 dependent한 variable이라고 가정을 했고, RGB는 3D 위치 정보, direction 정보에 dependent한 variable이라고 가정했기 때문에 이렇게 모델을 짰습니다. 이러한 방식 덕분에 물체의 같은 위치에 있는 포인트라 하더라도 바라보는 방향에 따라 다른 RGB 값을 가질 수 있게 되었습니다.

5. Volume Rendering with Radiance Field
MLP를 통해 얻어진 (r,g,b,σ)는 ray상의 존재하는 RGB,density를 의미합니다. 이 점들을 2차원상에 투영하여 우리가 보는 이미지 상에서 어떤 색으로 보여질지 판단하기 위해(=2D로 투영시킨 픽셀값을 얻기 위해) 저자는 Volume rendering 이라는 기법을 사용하였습니다. 계산식은 아래와 같습니다.
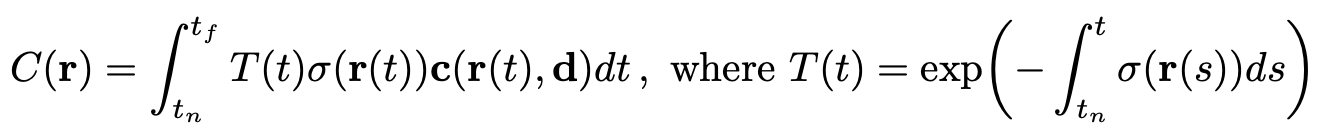
계산식을 하나씩 뜯어보면, 먼저 ray 상에서 계산이 시작되는 𝑡𝑛부터 𝑡𝑓까지 연속적으로 적분을 진행합니다.
r(): ray 정보
σ(): density 정보
T(t): 𝑡𝑛부터 t까지 빛이 투사되는 정도(투명성)
C(r): 최종적으로 예측된 픽셀값
그러나 위 식은 범위가 연속적이라는 가정하에 계산과정이고 실제로 컴퓨터 상에서 이러한 연속적인 계산이 이뤄지기는 어렵습니다. 그래서 저자는 실제로 𝑡𝑛부터 𝑡𝑓까지의 연속적인 범위를 N개의 덩어리(bin)로 균일한 간격으로 나누고, 각 덩어리 내에서 균일하게 무작위로 하나의 샘플을 추출하는 계층적 샘플링(hierarchical sampling)을 사용하였습니다.
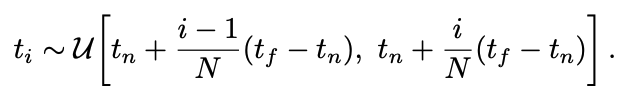
결과적으로 계층적 샘플링을 진행하여 이산개의 덩어리를 아래와 같이 계산하여 픽셀값을 계산합니다. 이렇게 적분을 진행하기 위해 이산개의 샘플 집합을 사용하였지만, 계층적 샘플링은 optimize 과정에서 MLP가 continuous한 위치에서 평가되기 때문에 continuous scene presentation을 나타낼 수 있다고 합니다.
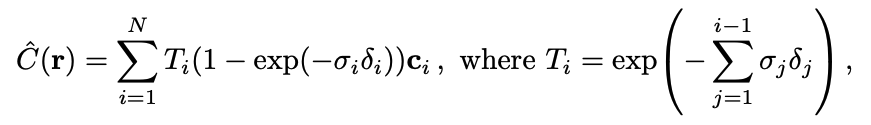
𝛿𝑖: 인접 샘플 간의 거리
6. Optimizing a Neural Radiance Field
앞서 Introduction에서 설명드렸다 싶이, 본 논문에서 저자는 NeRF를 최적화하는 basic implementation이 복잡한 scene에서 충분히 높은 해상도를 표현하지 못하며 카메라 ray 당 필요한 샘플 수가 비효율적이라는 것을 발견하였습니다.
그래서 저자는 Positional encoding과 Hierarchical Volume sampling을 통해 위 두가지 문제점을 해결하고 성능을 SOTA까지 끌러올렸다고 말합니다.
6.1 Positional encoding
우리가 흔히 알고있는 NLP에서 positional encoding은 hidden vector들의 모든 위치를 구분하기 위해 넣는 값이지만, 본 논문에서 positional encoding은 MLP의 입력으로 들어오는 5차원 입력값(x,y,z,θ,φ)을 더 높은 차원으로 바꿔서 high frequency scene content(물체의 경계선을)를 더 잘 표현할 수 있도록 하기위해 사용했습니다. Rahaman 등의 최근 연구에 따르면 심층 네트워크는 저주파수 함수를 학습하는 경향이 있다고 합니다. 그래서 저자는 MLP가 고주파수 함수를 더 잘 표현할 수 있도록(경계선을 더 잘 표현할 수 있도록) 입력값 (x,y,z,θ,φ)를 고주파수로 변환하는 Positional encoding 기법을 사용했습니다.
예를들어 설명해보겠습니다.

우리가 3이라는 값과 4라는 값을 MLP layer에 통과시켜보겠습니다. MLP는 weighted sum 과정이기 때문에 입력값이 비슷하면 출력값도 매우 비슷하게 나오게 됩니다. 이렇게 가까운 위치에 분포한 값이라도 다른 값으로 나오게 만들어주기 위해 저자는 low frequency부터 high frequency까지 sin,cos 함수를 사용해서 높은 dimension으로 바꿔줬습니다. 이렇게 높은 dimension으로 변환한 뒤 MLP에 넣어주면 앞서 설명했듯이 고주파수 영역을 잘 표현할 수 있게 됩니다.

그래서 실제로 positional encoding의 효과를 정성적으로 살펴보면 positional encoding 기법을 사용하지 않았을 때 high resolution scene을 잘 표현하지 못하는 것을 직관적으로 확인할 수 있습니다.
6.2 Hierarchical volume sampling
MLP의 출력(r,g,b,σ)을 2D projection하는 volume rendering에서 적분할 때 실제 컴퓨터에서 계산하기 위해 연속적인 구간을 N개의 이산적구간으로 나누어서 적분을 진행했습니다. 하지만 카메라 ray 당 필요한 샘플 수가 너무 많았기 때문에 computation cost가 많이 발생했습니다. 이러한 문제를 해결하기 위해 계층적 볼륨 샘플링(Hierarchical volume sampling) 기법을 사용하여 균일한 구간에서 무작위로 샘플링을 진행하여 computation cost를 낮췄습니다.
계층적 볼륨 샘플링은 거친(coarse) 네트워크와 정밀(fine) 네트워크라는 두 개의 네트워크 도입하였습니다.
- 계층적 샘플링을 사용하여 Nc 개의 포인트를 샘플링하고, 이 위치에서 거친 네트워크를 평가
(방정식 2와 3에 설명된 대로)
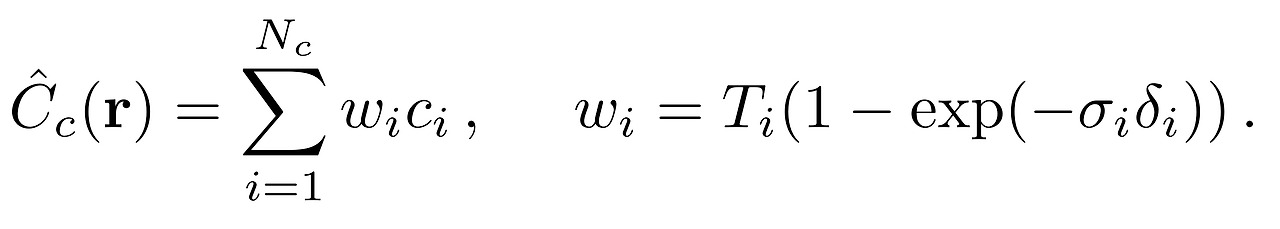
- 거친 네트워크의 출력에서 각 ray를 따라 density가 높은 값들을 위주로 다시 샘플링해서 Volume Rendering
(density가 높은 쪽에 분포한 point들이 실제로 의미있는 값이 많을 것이라는 가정을 수식에 담은 것) - NeRF는 이렇게 Coarse Model(C_c)을 돌려서 나온 값과 GT(실제값)와의 Loss, Fine Model(C_f)을 돌려서 나온 값과 GT와의 Loss 를 각각 구하여 더한 것으로 전체 Loss를 결정합니다.
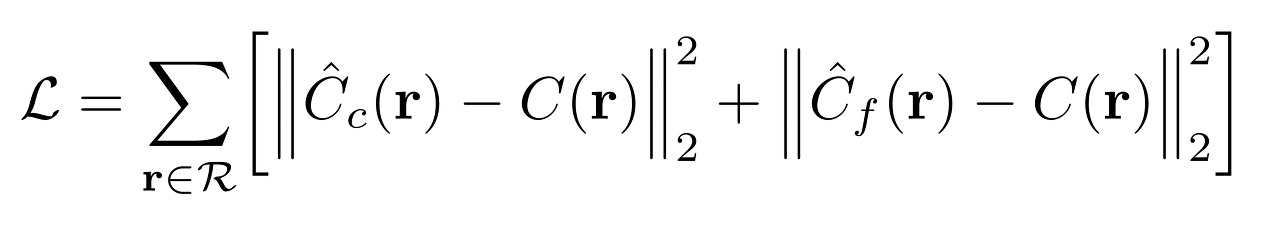
7. Result
본 논문에서는 Synthetic Rendering Dataset(Diffuse Synthetic 360, Realistic Synthetic 360) 2개와 Real Image Dataset(Real Forward-Facing) 1개 총 3개의 데이터셋에서 PSNR, SSIM, LPIPS를 측정하였습니다. 결과적으로 NeRF는 기존 SOTA model들을 제치고 Novel View Synthesis task에서 새로운 SOTA를 달성하였습니다.
- PSNR(Peak Signal to Noise Ratio): 두 이미지 간의 품질 차이를 측정하는 평가지표. MSE로 계산됨
- SSIM(Structural Similarity Index): 이미지의 구조적 유사성을 측정하는 평가지표. 밝기, 대비, 구조 세가지 요소를 비교함.
- LPIPS(Learned Perceptual Image Patch Similarity): 신경망을 사용하여 두 이미지 간의 지각적 유사성을 측정하는 평가지표. 사전 훈련된 CNN을 사용하여 이미지 패치간의 feature map을 비교

8. Conclusion
논문을 읽고 제가 내린 결론은 다음과 같습니다.
- 기존 복잡한 geometry를 잘 표현하지 못하던 문제를 해결함
- 기존 복잡한 geometry가 들어왔을 때 High resolution 표현을 잘 하지 못하던 문제를 해결함
- 기존 volume rendering의 고질적인 문제인 높은 computation cost 문제를 해결함
마지막으로 앞선 글을 통해 NeRF의 전체적인 동작과정을 이론적으로 이해했다면, 아래 동영상을 통해 다시한번 NeRF의 동작과정을 애니메이션을 통해 직관적으로 이해한다면 NeRF를 완전히 이해하실 수 있을 것 같습니다 :)
'논문 리뷰' 카테고리의 다른 글
| [논문리뷰]Integer Quantization: 모델 경량화 기본 (0) | 2024.08.21 |
|---|---|
| [논문리뷰]HDRUNet: 단일 프레임 HDR 챌린지 SOTA (0) | 2024.08.04 |
| [논문리뷰] DETR3D (CoRL 2022): multi-view 이미지를 이용한 3D OD (3) | 2024.07.24 |
| [논문 리뷰] PointNet (CVPR 2017): point cloud를 직접 처리 (0) | 2024.06.27 |
| [논문리뷰] HITNet (CVPR 2023) : cost volume aggregation 속도 향상 (0) | 2024.05.31 |