목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 2022년 Multimedia System이라는 저널에 개제된 2D Human Pose Estimation: A Survey 이라는 논문입니다. 이 논문을 리뷰하게된 이유는 최근 회사에서 Fish Pose Estimation을 통해 어류의 체중을 예측하는 task를 맡게 되었는데, Pose Estimation에 대한 전반적인 도메인 지식을 쌓기위해 이 논문을 리뷰하게 되었습니다. 논문 리뷰에 앞서 제가 이 논문을 읽고 내린 결론을 표로 정리해보면 다음과 같습니다.
논문을 읽고 내린 결론
2D Pose Estimation을 진행하는 방법에는 크게 Top-down 방식과 Bottom-up 방식이 있었고 각각의 장단점은 다음과 같습니다.
| 구분 | Top-down 방식 | Bottom-up 방식 |
| 장점 | 1. 높은 정확도 - 먼저 Object Detection을 수행하여 사람 Bounding Box를 정확히 찾은 후, 각 Bounding Box 내에서 Single Person Pose Estimation을 수행하기 때문에 개별 사람의 관절 위치를 더욱 정확하게 추정할 수 있음. - 특히 Deep Residual Learning for Image Recognition과 같은 강력한 Backbone Network를 활용하면 복잡한 장면에서도 높은 정확도를 유지 가능. 2. 확장성 - Object Detector와 Pose Estimator를 독립적으로 개선할 수 있어, 각 모듈의 성능 향상이 전체 Framework의 성능 향상으로 이어짐. 예를 들어, 보다 정확한 Object Detector를 사용하거나, 더 나은 Pose Estimation 알고리즘을 적용하는 방식으로 성능을 지속적으로 개선할 수 있음. |
낮은 계산비용 - 이미지 내 사람 수에 관계없이 Keypoint Detection을 먼저 수행한 후, 이후 Keypoint Grouping을 통해 Pose를 생성하기 때문에 사람 수가 많아도 비교적 효율적인 연산이 가능. 작은 모델 사이즈 - Object Detection 단계를 거치지 않으므로, 전체적인 모델 사이즈가 상대적으로 작음 |
| 단점 | 높은 계산 비용 - 각 사람의 Bounding Box마다 Pose Estimation을 수행해야 하므로, 이미지 내 사람 수가 많을수록 계산량이 증가함. 특히 실시간 응용 분야에서는 이러한 높은 연산 비용이 큰 문제가 될 수 있음. Object Detection 의존성 - Object Detector의 성능이 전체 Framework의 성능에 직접적인 영향을 미침. Object Detection이 실패하거나 부정확한 Bounding Box를 생성하는 경우, Pose Estimation의 정확도가 크게 저하될 수 있음. 군중 장면에서의 어려움 - 사람들이 밀집된 장면에서는 Bounding Box가 겹칠 가능성이 높아지며, 이로 인해 Pose Estimation의 성능이 저하될 수 있음. |
낮은 정확도 - Keypoint Detection 단계에서 Object Detection을 수행하지 않기 때문에 개별 사람에 대한 Contextual Information이 부족할 수 있음. 이로 인해 관절 위치 추정의 정확도가 Top-Down 방식에 비해 낮을 가능성이 있음. Keypoint Grouping 문제 - Keypoint Grouping 과정에서 잘못된 연결이 발생하기 쉬움. 특히 사람들이 서로 가깝게 위치한 경우, 다른 사람의 관절을 자신의 Pose에 잘못 연결하는 오류가 발생할 수 있음. |
3. Network Architecture Design Methods
앞서 설명드린 대로 2D Pose Estimation을 진행하는 방법은 크게 두가지로 나뉩니다.
| 방식 | 설명 | 단계 1 | 단계 2 |
| Top-down (하향식) 방식 | 먼저 객체를 검출한 후, 각 객체 내부에서 Keypoint를 찾는 방식 | 이미지에서 객체의 Bounding box 검출 | Bounding box 내에서 단일 인물 자세 추정 |
| Bottom-up (상향식) 방식 | 먼저 Keypoint를 검출한 후, 이를 그룹화하여 인스턴스를 식별하는 방식 | 신원없는 Keypoint 검출 | 서로 다른 인물 instance로 keypoint를 그룹화 |
3.1 Top-down framework

3.1.1 Regression-based Method
- 회귀 기반 접근 방식은 입력 이미지에서 관절의 위치를 2차원 좌표 (x, y)로 직접 예측하는 방법을 말합니다.
(즉, 각 관절을 하나의 점으로 표현합니다) - 최근에는, Graph Convolutional Network (GCN) Semi-Supervised Classification with Graph Convolutional Networks을 활용하여 인체의 관절과 뼈대 간의 관계를 모델링하고, 이를 통해 보이지 않는 관절을 추정하는 방법도 연구되고 있습니다.
- 단 하나의 점을 추론한다는 점에서 계산 효율성이 높고 실시간 적용에 유리하다는 장점을 갖고있지만, 신체부위의 면적을 고려하지 못한다는 단점을 가지고 있습니다.
- 예를들어, 사람의 손목은 단순한 점이 아니라 실제 넓이를 가진 영역입니다. Regression-based 방법은 이러한 면적 정보를 고려하지 않고 관절을 단일 2D 점으로 추론하기 때문에 관절 위치의 정확도가 떨어진다는 단점을 갖고 있습니다.
- 또한 이미지 해상도가 낮거나 occlusion 문제가 발생했을 때 정확도가 떨어지는 단점을 갖고 있었습니다.
- 그래서 이러한 문제점들을 해결하기 위해 Heatmap-based method가 도입되었습니다.
3.1.2 Heatmap-based Method
- 히트맵 기반 접근 방식은 관절의 위치를 2차원 좌표로 직접 예측하는 대신, 이미지 내 각 위치가 특정 관절일 확률을 나타내는 Heatmap을 예측하는 방식을 말합니다.
(즉, Heatmap 상의 각 위치가 해당 관절일 확률을 나타냅니다.) - 그렇다면 히트맵은 앞서 설명했던 Regression-based 방식의 단점을 어떻게 해결했을까요?
- Regression-based 방식은 면적정보를 고려하지 않고 관절을 추론하기 때문에 keypoint 정확도가 떨어진다고 설명드렸습니다.
- 그래서 히트맵은 관절이 있을만한 영역을 가우시안 확률분포로 추론하고 확률이 1에 가장 가까운 point를 최종 관절위치로 추론하였습니다. 이렇게 하면 관절 위치에 대한 불확실성을 히트맵에 반영할 수 있으며 이는 곧 면적 정보를 간접적으로 고려하게 되는 효과를 얻습니다!
- 또 Regression-based 방식은 이미지 해상도가 낮거나 occlusion 문제가 발생했을 때 정확도가 떨어진다고 설명드렸습니다.
- 그래서 히트맵 방식은 주변 픽셀과의 관계를 고려하여 관절 위치를 추정합니다.
- 예를 들어, 팔꿈치 Heatmap 주변에 팔 Heatmap이 있다면, 팔꿈치의 위치를 더 정확하게 추정할 수 있습니다.
(Regression-Based 방법은 이러한 맥락 정보를 활용하기 어렵기 때문에 occlusion 발생 시 정확도가 떨어지게 됩니다) - 이렇게 히트맵 방식은 Regression-based 방식의 문제점을 해결했습니다.
[84]는 혼잡한 장면에서 단일 인물 경계 상자가 여러 인물을 포함하는 경향이 있어 포즈 탐지 성능을 악화시킨다고 지적합니다. 이 문제를 해결하기 위해 [84]는 조합 후보 포즈 탐지기를 사용하여 여러 개의 피크를 가진 히트맵을 예측하고, 그래프 네트워크를 사용하여 전체 관절 연관을 수행합니다.
3.1.3 Video-based Method
비디오 내에서 Pose Estimation 작업은 여러가지 고려사항(카메라의 이동, 빠른 객체 이동, 초점 흐림)이 존재합니다. 반면에 정적 이미지와 달리 비디오 프레임 간에 풍부한 시간적 단서(시간적 의존성, 기하학적 일관성)이 존재하기 때문에 Pose Estimation에 유용한 정보를 포함합니다.
- 대부분의 기존 방법은 정적 이미지로 모델을 훈련하고 video 개별 frame에 대한 Pose Estimation을 진행합니다.
- 이미지 기반 모델로 비디오 Pose Estimation을 하는 것은 동영상 프레임간의 시간적 의존성을 고려하지 못하기 때문에 좋지 못한 성능을 내왔습니다.
- 이러한 문제점을 해결하기 위해 최근 연구에서는 시간적 정보를 활용하여 Pose Estimation 정확도를 개선하였습니다.
- 시간적 정보를 활용하는 방법에는 크게 네가지로 구분됩니다.
1. Optical flow-based method
2. RNN-based method
3. Pose tracking-based method
4. Key frame-based method
Optical flow
Optical Flow는 연속된 이미지 프레임 간의 픽셀 이동을 추정하는 기법을 말합니다.
시간 t Frame의 어떤 픽셀이 의 어떤 픽셀과 대응이 되는 지 찾고 motion vector를 구하여 물체의 움직임을 추정하는 원리입니다.
이러한 optical flow를 추정하기 위해서는 현실을 훼손하지 않는 범위 내에서 적절하게 가정을 세워야 합니다. Optical flow의 전제 조건 2가지는 다음과 같습니다.
- ① color/brightness constancy : 어떤 픽셀과 그 픽셀의 주변 픽셀의 색/밝기는 같음을 가정으로 세웁니다.
- ② small motion : Frame 간 움직임이 작아서 어떤 픽셀 점은 멀리 움직이지 않는 것을 가정으로 세웁니다.
이러한 전제조건은 사실 현실세계에서는 한계(배경변화, 노이즈에 민감)가 명확하기 때문에 최근에는 CNN과 optical flow를 결합하여 여러 프레임에서 feature를 시간순으로 정렬하고, 정렬된 feature를 활용하여 개별 프레임에서 Pose Estimation을 개선하는 연구가 제안되었습니다[131].
RNN
RNN은 시계열 데이터 처리에 특화된 모델입니다. 따라서 비디오 프레임과 같이 시간 순서대로 나열된 데이터의 temporal contexts를 모델링 할 수 있기 때문에 Pose Estimation task에도 도입되었습니다. 각 프레임의 Pose Estimation 결과는 현재 입력뿐 아니라 과거 프레임의 추정 결과와 결합되므로 연속된 프레임 간의 temporal dependency를 활용하여 Pose Estimation 정확도를 개선하였습니다.
하지만 이러한 RNN 기반 방법은 각 사람의 temporal contexts를 추출하는 과정에서 다른 사람의 영향을 받을 수 있기 때문에 Multi-person 비디오에 적용할 수 없다는 큰 단점이 있습니다.
Pose Tracking
Pose Tracking은 RNN의 문제를 해결하기 위해 제안되었습니다. 이 방법은 각 비디오 frame에서 각 개인을 위한 tracklet을 설정하여 관련없는 다른 사람들의 정보를 필터링합니다. 이 방법은 Multi-person Pose Estimation에서 좋은 성능을 보여줬지만, tracklet 생성을 위해 feature similarity, pose similarity을 계산해야 하므로 계산 오버헤드가 존재한다는 단점이 있습니다.
Key Frame Optimization
Key Frame Optimization 방법은 tracklet의 시간적 정보+핵심 프레임으로 현재 프레임의 Pose Estimation 정확도를 개선하는 방법입니다. 비디오에서 사람의 자세를 정확하게 파악하는 것은 어려운 문제입니다. 왜냐하면 카메라 움직임, 물체의 빠른 움직임, 흐릿함 등으로 인해 프레임의 품질이 떨어질 수도 있기 때문입니다. 그래서 Key Frame Optimization 방법론은 비디오의 모든 프레임을 다 똑같이 중요하게 생각할 필요는 없다는 아이디어에서 출발합니다. 어떤 프레임은 자세를 파악하기에 유용한 정보를 많이 담고 있는 반면, 어떤 프레임은 그렇지 않을 수 있기 때문입니다.
원리는 다음과 같습니다.
- 1단계 핵심 프레임(Key Frame) 선택: 비디오에서 자세를 파악하는 데 가장 도움이 되는 몇몇 프레임을 선택합니다. 이 프레임들을 "핵심 프레임"이라고 부릅니다. 핵심 프레임은 일반적으로 자세가 뚜렷하게 잘 보이는 프레임, 중요한 움직임이 포함된 프레임 등이 될 수 있습니다.
- 2단계 Pose Warping: 선택된 핵심 프레임에서 추출한 Pose 정보를 현재 프레임에 맞게 변환합니다. 예를들어, 핵심 프레임의 자세가 현재 프레임과 다른 각도에서 촬영되었다면 해당 각도 차이를 보정합니다.
- 3단계 Pose Aggregation: 여러개의 핵심 프레임에서 현재 프레임으로 Warping된 Pose 정보를 통합하여 최종 자세를 예측합니다. 예를들어, 현재 프레임과 시각적으로 유사한 핵심 프레임에 더 높은 가중치를 부여하여 Pose 정보를 통합합니다.
- 4단계 현재 프레임 Pose 보정: 3단계까지 진행하여 통합된 Pose 정보(참고자료)를 이용하여 현재 프레임의 Pose를 개선합니다. 이 과정은 여러 방법으로 이루어질 수 있습니다. 예를들어, 평균화(핵심 프레임의 자세와 현재 프레임의 자세 정보를 평균), 가중 평균(현재 프레임과 시각적으로 유사한 핵심 프레임에 더 높은 가중치 부여) 등이 있습니다.
왜 Key Frame Optimization을 사용하는가?
첫번째 이유는 정확도 향상입니다. 핵심 프레임은 자세 추정에 중요한 정보를 담고 있기 때문에, 이를 활용하면 현재 프레임의 Pose Estimation 정확도를 높일 수 있습니다. 두번째 이유는 계산비용 때문입니다. 모든 프레임을 다 분석하는 대신, 핵심 프레임만 선택적으로 활용하므로 계산 비용을 줄일 수 있습니다.
예를 들어, 태권도 동작 비디오에서 발차기 자세를 추정한다고 가정해 보겠습니다.
문제: 비디오는 여러 프레임으로 구성되어 있으며, 발차기 동작이 흐릿하게 보이는 프레임도 있습니다.
- 핵심 프레임 선택: 발차기 자세가 가장 뚜렷하게 보이는 프레임을 핵심 프레임으로 선택합니다. 예를 들어, 다리가 완전히 뻗은 순간의 프레임을 선택할 수 있습니다.
- 자세 개선: 선택된 핵심 프레임의 자세 정보를 사용하여 다른 프레임의 자세를 더 정확하게 추정합니다. 예를 들어, 핵심 프레임의 다리 위치를 기준으로 다른 프레임의 다리 위치를 보정할 수 있습니다.
3.1.4 Model Compression-based Method
모바일이나 Jetson nano와 같이 저전력 장치에서 모델추론을 하기 위해 경량화된 Pose Estimation 모델이 많이 연구되었습니다.
- Teacher-student Model: 파라미터 크기가 큰 Teacher 네트워크를 이용하여 파라미터 크기가 작은 Student 모델을 지식 증류 방식으로 학습하여 경량화된 모델(student model)을 얻는 방법입니다.
- 대표적으로 HRNet의 파라미터를 줄이기 위해 기존 블록을 shuffle-block으로 대체하거나 계산비용이 많이 드는 point-wise cnnd을 대체하기 위해 conditional channel weighting module을 도입합니다.
3.1.5 Summary of Top-down Framework
지금까지 설명드린대로 Top-down 방식은 이미지에서 인물 bbox를 추론하고, bbox 내에서 단일 인물의 keypoint detection을 수행합니다. 따라서 bbox를 추론하는 detector가 모델 성능에 큰 영향을 끼치게 됩니다. 하지만 이러한 방식에도 문제점이 존재하는데요. [84]에 따르면 혼잡한 장면에서 단일 인물 bbox가 여러 인물을 포함하는 경향이 있어 포즈 탐지 성능을 악화시킨다고 지적합니다. 이 문제를 해결하기 위해 [84]는 조합 후보 포즈 탐지기를 사용하여 여러 개의 피크를 가진 히트맵을 예측하고, 그래프 네트워크를 사용하여 전체 관절 연관을 수행합니다.
3.2 Bottom-up framework
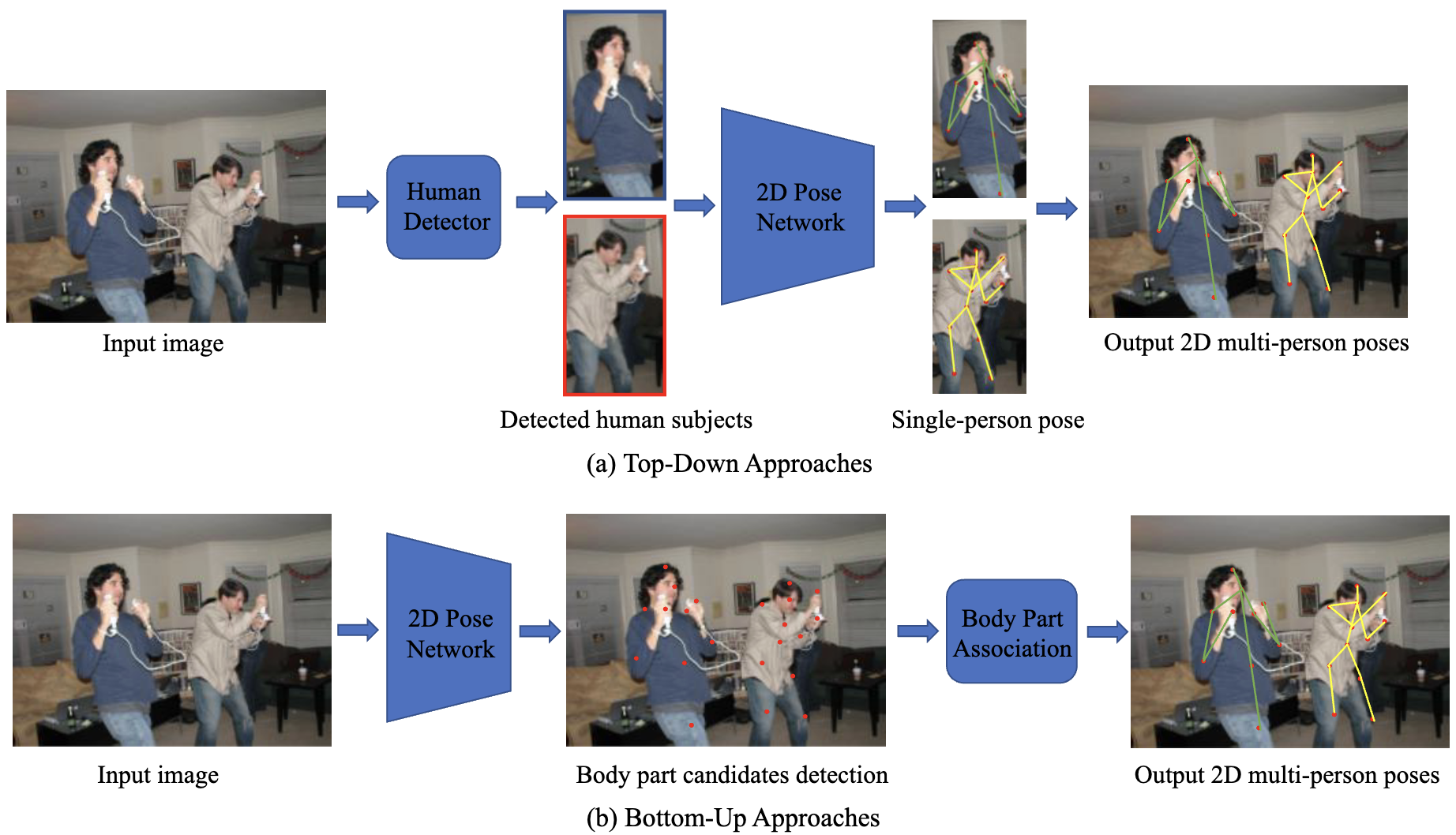
Bottom-up 방식과 Top-down 방식 간의 차이점은 detector를 사람 bbox 탐지에 사용하는지 여부입니다. Top-down 방식과 비교하여 Bottom-up 방식은 인간 탐지에 의존하지 않고 원본 이미지에서 직접적으로 주요 keypoint detection을 수행하여 계산 오버헤드를 줄입니다. 하지만 이 절차는 새로운 문제를 만들게 되는데요. 어떻게 추정된 관절의 정체성을 판단할 것인가? 입니다. 추정된 주요 점의 정체성을 결정하는 방법에 따라, 우리는 Bottom-up 방식을 인간 중심 회귀 기반 [40, 123-125], 연관 임베딩 기반 [19, 69, 106, 121], 그리고 부분 필드 기반 [9, 55, 62, 70, 77, 78, 85, 105, 132, 133, 136, 173] 접근 방식으로 나눌 수 있습니다.
3.2.1 Human Center Regression-based Method
- Human Center Regression 방법은 이미지 내에서 사람의 중심점을 찾아 개별 사람을 식별하는 방법입니다. 사람의 중심점을 예측하고, 그 중심점을 기준으로 다른 관절들의 위치를 추정합니다.
- 하지만 이 방법은 Keypoint Detection + Center point regression + keypoint association과 같이 총 3단계로 구성됩니다.
따라서 bottom-up 방식의 장점인 모델 구조의 단순성이 떨어진다는 단점이 있을 것 같습니다.
3.2.2 Associate Embedding-based Method
- Associate embedding 방법은 각 keypoint에 입베딩 벡터를 부여하고, 같은 사람에 속하는 keypoint들 끼리 유사한 임베딩 값을 갖도록 학습시키는 방법입니다. Face Recognition 과정을 떠올리면 이해가 쉬울 것 같습니다!
- 하지만 개인적으로 Face Recognition 모델로 서비스를 만들면서 느꼈던 점은 각 얼굴의 임베딩 벡터를 계산하는데 매우 많은 연산비용이 든다는 점이었습니다. 그래서 실시간 서비스에는 적합하지 않은 방식이라고 생각합니다. 유사하게 각 keypoint에 임베딩 벡터를 부여하는 과정도 매우 많은 연산 비용이 발생할 것이고, 많은 양의 학습 데이터를 요구할 것으로 예상됩니다.
3.2.3 Part Field-based Method
- Part Field 방법은 탐지된 keypoint 사이의 연결 강도를 나타내는 part affinity field를 예측하는 방법입니다. 각 키포인트끼리의 연결 강도를 예측하고 Greedy 알고리즘을 이용하여 키포인트들을 연결합니다. 이렇게 하면 가장 가능성이 높은 연결부터 순서대로 연결되어 그룹화됩니다.
4. Network Training Refinement
4.1 Data Augmentation Techniques
2D Human Pose Estimation에는 일반적으로 random-rodation, random-scale, random truncation, horizontal flipping, random information dropping 및 조명 변화 등의 augmentation 기법들이 사용됩니다.
4.2 Multi-Task Training Strategies
Multi-task learning은 여러 관련 작업 간의 표현을 공유하여 유용한 특징을 추출하는 것을 목표로 합니다. 예를들어, 사람의 몸을 의미론적 part(머리,팔,다리 등)로 분할하는 human parsing 모델의 표현과 human pose estimation 모델의 표현을 결합하여 성능을 높이는 방법이 있습니다.
4.3 Loss Function Constraints
딥러닝 모델에서 손실함수는 모델이 학습해야 할 방향성을 제시하므로 모델 성능에 큰 영향을 끼칩니다.
- 일반적인 손실함수: 2D Human Pose Estimation에서 일반적으로 사용하는 손실 함수는 L2 거리입니다. L2 거리는 예측된 히트맵과 실제 히트맵 간의 유클리드 거리를 측정하여 오차를 계산합니다.
- 구조적 정보를 활용한 손실함수: Multi-Scale Structure-Aware Network에서는 인체 구조 정보를 활용하는 손실 함수를 제안합니다. 이는 키포인트 자체의 정확도뿐만 아니라, 키포인트 간의 관계를 고려하여 학습을 유도합니다.
구조적 정보를 활용한 손실함수
이 부분에서 물고기의 구조적인 정보를 활용한 손실함수를 도입하면 Pose Estimation 성능을 높일 수 있지 않을까? 라는 생각이 들었습니다.
- Hard Keypoint Mining 손실함수: Cascaded Pyramid Network에서는 어려운 키포인트(Hard Keypoint)에 대한 손실 가중치를 높이는 방식을 사용합니다. 이는 모델이 학습하기 어려운 키포인트에 더 집중하여 전체적인 성능을 향상시키는 전략입니다.
- Distillation 손실함수: Combined Distillation Pose에서는 HRNet의 성능 향상을 위해 구조적 손실(STLoss), pairwise inhibition 손실(PairLoss), 확률 분포 손실(PDLoss)을 결합한 distillation loss를 제안합니다. 특히 PairLoss는 혼잡한 환경에서 유사한 joint를 구별하는 데 도움을 줍니다.
5. Post Processing Approaches
5.1 Quantization Error
양자화 오차는 2D Human Pose Estimation에서 heatmap 기반의 포즈 표현을 사용할 때 발생하는 문제입니다. 이 오차는 heatmap에서 관절의 2D 좌표를 추출하는 과정에서 생기며, heatmap이 항상 이상적인 가우시안 분포를 따르지 않아 좌표 계산의 정확도를 떨어뜨립니다.
- Heatmap 기반 방법에서 양자화 오류의 원인은 Heatmap에서 좌표로 변환하는 과정에서 발생합니다.
- 예측된 heatmap이 항상 표준 가우시안 분포를 따르지 않아, 여러 피크 값을 가질 수 있기 때문입니다.
- 이에대한 해결방법은 크게 두가지로 나뉩니다.
- 첫째, 분포 인식 아키텍처(Distribution-aware architecture): Heatmap 분포 조정을 통해 예측된 heatmap 형태를 조정하고, 좌표 디코딩 방법을 개선하여 최종 키포인트 위치를 정확하게 얻습니다.
단위 길이 기반 데이터 처리: 픽셀 대신 단위 길이를 기준으로 데이터를 처리하여, 추론 시 뒤집기를 수행할 때 포즈 결과가 정렬되도록 합니다. - 둘째, 미분 가능한 알고리즘 설계: Soft-argmax 함수를 사용하여 특징 맵을 키포인트 좌표로 직접 변환하거나, 적분 방법을 통해 heatmap에서 좌표로의 변환 시 미분 불가능 문제를 해결합니다.
5.2 Pose Resampling
Pose Resampling)은 초기 Pose Estimation 결과를 바탕으로, 가능한 여러 포즈 후보들을 생성하고 평가하여, 최종적으로 더 정확하고 현실적인 포즈를 추정하는 방법을 말합니다. 원리는 다음과 같습니다.
- 초기 Pose 잡기: 인공지능 모델이 사진이나 영상 속 사람의 뼈대 위치를 대략적으로 파악합니다. 마치 처음 그림 그릴 때 스케치하는 것과 같습니다.
- 자세 후보 여러 개 만들기: 처음 잡은 뼈대 위치를 조금씩 바꿔서 여러 가지 가능한 자세를 만들어 냅니다. 약간씩 다른 자세들을 여러 개 준비하는 것입니다.
- 자세 평가하기: 만든 자세 후보들이 실제 사람의 모습과 얼마나 비슷한지, 인체 구조에 맞는지 등을 평가합니다. 예를 들어, "다리가 너무 꺾이지 않았는지", "팔이 어색하게 꼬이지 않았는지" 등을 확인합니다. 포즈를 평가하는 방법에는 이미지 기반 평가, 포즈 구조 기반 평가, 시간적 일관성 기반 평가 등이 있습니다.
- 최고의 자세 고르기: 평가 결과가 가장 좋은 자세를 선택하거나, 여러 자세를 적절히 섞어서 최종 자세를 결정합니다. 스케치를 바탕으로 그림을 다듬어 완성하는 과정과 같습니다.
6. Datasets and Evaluation
6.1 Datasets
각 데이터셋에 대한 자세한 설명은 논문을 참고해주시면 감사하겠습니다.
6.2 Evaluation


7. Discussion
해결해야 할 과제
- 모델의 일반화 능력 부족: 복잡한 환경에서 모델이 제대로 작동하지 않는 경우가 많습니다. 예를 들어, 포즈가 가려지거나 사람들끼리 겹쳐 보이는 상황, 그리고 빠르게 움직여서 화면이 흐릿하게 보이는 경우에 정확도가 떨어집니다. 이러한 문제를 해결하기 위해선 image-based human pose estimation 모델은 사람의 신체 구조에 대한 사전 지식을 활용해야 하며, video-based human pose estimation 모델은 시간적인 흐름을 고려하여 시각 정보가 부족한 프레임에서 포즈를 복원해야 합니다.
- 학습 데이터 부족: 현재 이미지 데이터셋은 충분하지만, 비디오 데이터셋은 여전히 부족한 상황입니다. 특히 가려진 관절에 대한 정확한 위치 정보가 없는 경우가 많아, 모델이 가려지거나 겹쳐진 포즈를 학습하기 어렵습니다. 춤이나 수영과 같은 특정 동작에 대한 데이터셋 부족도 해결해야 할 문제입니다. 특정 도메인에 대한 데이터셋을 구축하는 것이 2D HPE의 활용도를 높이는 데 중요합니다.
'논문 리뷰' 카테고리의 다른 글
| [논문리뷰]CrowdPose : 군중 데이터에서 Pose Estimation (0) | 2025.03.20 |
|---|---|
| [논문리뷰]HRNet for Human Pose Estimation: 고해상도 표현을 이용한 포즈 추정 (3) | 2025.01.31 |
| [논문리뷰]Tracking Persons-of-Interest via Unsupervised Representation Adaptation: 제약없는 동영상에서 얼굴 추적 (0) | 2024.12.29 |
| [논문리뷰]FaceNet: Face Recognition의 기본모델 (2) | 2024.12.12 |
| [논문리뷰]UniDepth: 일반화된 Monocular Metric Depth Estimation! (2) | 2024.11.20 |