목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 2019년 CVPR에 개제된 Deep High-Resolution Representation Learning for Human Pose Estimation 이라는 논문입니다. 이 논문을 리뷰하게된 이유는 최근 Fish Pose Estimation을 통해 어류의 체중을 예측하는 서비스를 접하게 되었는데, 내부적으로 어떻게 구현된건지 궁금증이 생겨서 이 논문을 리뷰하게 되었습니다. 논문 리뷰에 앞서 이 논문을 한마디로 정리하면 다음과 같습니다.
해상도를 낮추는 과정없이, 처음부터 끝까지 고해상도를 유지함으로써 Pose Estimation 성능을 끌어올린 논문
0. Background

일반적으로 heatmap 기반으로 keypoint를 detection하는 neural network의 학습/추론 과정을 간단하게 설명해보겠습니다.
- 학습(Training) 단계
- (a) 입력 데이터 준비: 원본 이미지와, 연어 위에 어떤 좌표가 정답인지 표시된 히트맵(라벨) 형태를 준비합니다. 정답 히트맵은 해당 지점 주변이 밝게(1에 가깝게), 나머지는 어둡게(0에 가깝게) 만들어놓은 2D 가우시안 형태를 자주 씁니다.
- (b) 네트워크에 입력: 이미지를 HRNet(또는 다른 CNN)에 통과시키면, 마지막 레이어 쪽에서 히트맵 크기의 출력이 나옵니다.
- (c) 손실(오차) 계산: 네트워크 출력 히트맵과 정답 히트맵을 비교(예: Mean Squared Error)하여 얼마나 비슷한지 측정합니다.
- (d) 역전파(Backpropagation): 계산된 오차를 기준으로 네트워크의 가중치를 조정하여, “연어의 특정 지점”을 더 정확히 예측하도록 학습을 반복합니다.
- 추론(Inference) 단계
- 학습된 모델에 이미지를 넣으면, 각 지점이 있을 확률을 2D 형태로 시각화한 히트맵이 나옵니다.
- 붉은색으로 표시된 중앙부는 해당 지점이 있을 확률이 가장 높은 위치를(1에 가까움), 파란색·초록색 등으로 갈수록 낮은 확률(0에 가까움) 영역을 나타내게 됩니다.
- 최종적으로 히트맵에서 가장 ‘값’이 큰 위치(1에 가까운)를 찾아서, 그 좌표가 CNN이 찾아낸 랜드마크 혹은 관심 지점이 됩니다.
1. Introduction
Previous method for pose estimation
- Pose Estimation을 위한 기존 방법들은 고해상도에서 저해상도로 이미지를 변환하며 특징을 추출한 뒤 다시 고해상도로 변환하면서 특징을 추출하는 방식을 사용함(전역 특징, 지역 특징 사용)
- Stacked Hourglass Network[40]은 원본 이미지 입력-> conv 연산(저해상도로 변환하며 특징추출) -> nearest neighbor upsampling and skip connections (고해상도로 변환하면서 특징추출) -> 이 과정을 여러번 반복
- Simple Baseline for Human Pose Estimation[72]는 원본 이미지 입력 -> conv 연산(저해상도로 변환하며 특징추출) -> transposition conv 연산(고해상도로 변환하면서 특징추출)
- 하지만 이러한 방법들은 다운샘플링+업샘플링 과정에서 세부(지역적인)정보가 손실되는 문제점이 있었음
Proposed method for pose estimation

- 이러한 문제를 해결하기 위해 네트워크 처음부터 끝까지 고해상도를 유지하는 HRNet을 제안함
- 먼저 High-resolution subnetwork를 첫번째 stage로 시작함
- 이후 점차적으로 High-to-low-resolution subnetwork를 하나씩 "병렬로" 추가함
- 마지막으로 병렬로 추가된 여러개의 High-to-low-resolution subnetwork로부터 representation 정보를 주고 받으면서 반복적으로 multi-scale fusion을 진행함
- 이로써 HRNet은 기존 네트워크들과 비교하여 크게 두가지 이점을 갖게됨
- 첫째, 처음부터 끝까지 고해상도를 유지할 수 있어서 예측된 heatmap은 공간적으로 더 정확함
- 둘째, 저해상도 표현과 고해상도 표현을 단순히 결합 하는게 아닌, 반복적으로 multi-scale fusion을 수행하기 때문에, 고해상도 표현과 저해상도 표현이 각각 풍부해지고 결과적으로 예측된 heatmap은 더 정확함
2. Related Work
2.1 기존 CNN 기반 접근방법
CNN 기반의 Pose Estimation method는 크게 두가지로 나뉩니다. Keypoint 위치를 직접 찾는 방법과 히트맵을 이용하는 방법입니다.
CNN을 기반으로 하는 이 두가지 방법은 세 가지 구성요소로 이루어져 있습니다.
- Stem Network: 해상도를 낮추면서 특징을 추출하는 역할
- Main Network: 해상도를 일정하게 유지하면서 특징을 추출하는 역할을 함. 또한 네트워크의 해상도가 입력 해상도보다 낮고, 출력 또한 입력보다 낮은 해상도로 생성됨
- Regressor: Main Network에서 얻어진 특징을 사용하여 히트맵 or 직접 keypoint 좌표 회귀하는 역할
2.2 High-to-Low & Low-to-High 방식
- High-to-Low 과정은 입력 이미지를 저해상도로 변환하고 전역적인 특징을 추출하는 것임
- Low-to-High 과정은 저해상도 이미지를 고해상도로 변환하면서 지역적인 특징을 추출하는 것임
2.3 Multi-scale fusion 방식
- 가장 직관적인 Multi-scale fusion 방식은 동일한 이미지를 여러 해상도로 변환하고 네트워크에 입력한 뒤 출력결과를 결합하는 것임
- Stacked Hourglass[39]과 후속 연구들은 하위 계층의 특징을 상위 계층 특징과 결합하여 활용함
- Cascaded Pyramid Network[11]에서는 저해상도-고해상도 특징을 단계적으로 결합하는 GlobalNet과 이를 추가로 정제하는 RefineNet 구조를 사용함
- HRNet에서는 Multi-scale fusion을 반복적으로 수행하는 구조를 사용함
2.4 중간 히트맵 감시(Intermediate Supervision) 방식
- 중간 단계에서 히트맵을 생성하고 이를 학습하는 방식은 CNN의 학습을 도와 성능을 향상시켰음
- Hourglass approach[39], Convolutional Pose Machine[69] 논문에서 중간 히트맵을 하위 네트워크의 입력으로 사용하여 성능을 끌어올림
2.5 Our Approach
- 기존 방법들은 해상도를 낮춘 후 다시 높이면서 특징을 추출하여서 세부(지역적인)정보 손실이 발생하지만, HRNet은 처음부터 끝가지 고해상도를 유지하기때문에 세부(지역적인) 정보 손실이 없음
- 기존 방법들은 저해상도 특징과 고해상도 특징을 단순히 결합하였지만, HRNet은 반복적인 Multi-scale fusion을 수행하여 고해상도 표현을 더욱 풍부하게 만듦
다운샘플링-> 업샘플링 과정에서 왜 세부(지역적인)정보가 손실될까??
1. 다운 샘플링 과정
- 다운 샘플링이란 Conv + Pooling을 통해 이미지 크기를 줄이는 과정임
- 네트워크가 더 넓은 범위의 특징(global feature)을 학습할 수 있도록 하기위해 사용됨
- 그러나 다움샘플링을 하면 전체 픽셀수가 줄어들기 때문에 작은 구조가 희미해지거나 사라질 가능성이 있음
- 예를들어, 손가락 끝이나 눈썹과 같이 작은 형상정보가 손실됨
2. 업 샘플링 과정
- 업 샘플링이란 다운 샘플링을 통해 축소된 feature map을 다시 고해상도로 복원하는 과정임
- Transposed conv, Bilinear upsampling, Nearest neighbor upsampling 등이 사용됨
- 그러나 다운 샘플링 과정에서 잃어버린 세부 정보를 다시 복원하는건 불가능함
- 업샘플링은 픽셀 간의 보간(Interpolation) 방식을 사용하기 때문에 원본에서 선명했던 경계가 흐려지는 Blur 현상이 많이 발생함
- Transposed conv를 사용할 경우, 네트워크가 원래 없던 픽셀값을 생성해야 하기 때문에 잘못된 특징이 추가될 가능성이 있음
- 이로인해 keypoint가 어긋나거나, 잘못된 위치에서 강한 히트맵이 발생할 수 있음
3. Approach
3.1 Sequential multi-resolution subnetworks
- 기존 Pose Estimation 네트워크들은 High-to-Low subnetwork를 직렬로 연결하는 구조를 사용함
- 각 subnetwork(stage)는 conv layer들의 시퀀스로 이루어져 있고, 인접한 subnetwork 사이에는 down-sampling layer가 있어서 해상도를 절반으로 줄여주었음
- 예를들어, 4개의 subnetwork(stage)로 구성된 네트워크는 다음과 같이 표현됨

- Nsr은 s번째 subnetwork의 r번째 해상도 subnetwork를 의미함
3.2 Parallel multi-resolution subnetworks
- 처음에는 고해상도 subnetwork만 사용하고, 이후 stage에서 점진적으로 저해상도 subnetwork를 추가함
- 각 stage에서 다중 해상도 subnetwork를 병렬로 배치해서 정보를 서로 교환하는 방식임
- 예를들어, 4개의 병렬 subnetwork로 구성된 네트워크는 다음과 같이 표현됨

3.3 Repeated multi-scale fusion
- 각 병렬 subnetwork 간 정보를 지속적으로 교환할 수 있도록 Exchange Units을 도입함
- 각 subentwork가 반복적으로 다른 subnetwork의 정보를 수신하여 자신의 표현을 더욱 풍부하게 만들도록 설계됨
- 예를들어, 3번째 stage에서 3개의 Exchange Block이 포함된 경우 다음과 같이 표현됨

- 즉, 고해상도 정보를 저해상도 subnetwork로 전달 -> 저해상도 정보를 고해상도 subnetwork로 전달 -> 각 subnetwork가 지속적으로 정보를 주고 받으면서 자신의 표현을 더욱 풍부하게 강화함
3.4 Heatmap Estimation
- 최종적으로 마지막 Exchange Unit에서 출력된 고해상도 표현(feature map)을 활용하여 히트맵을 회귀(regression)함
- 손실 함수는 MSE(Mean Squared Error)를 사용하여 예측된 히트맵과 GT 히트맵을 비교하며 학습함
- 실제 GT 히트맵은 각 키포인트 위치를 중심으로 한 2D gaussian distribution을 적용하여 생성함
3.5 Network Instantiation
- HRNet은 총 4개의 stage로 구성되며, 각 stage에서 해상도가 점진적으로 절반으로 감소하고, 반대로 채널 수(width)는 2배씩 증가함
- 첫번째 stage: 4개의 residual block으로 구성됨
- 두번째, 세번째, 네번째 stage: 각각 1, 4, 3개의 Exchange block으로 구성됨
- 최종적으로 총 8개의 Exchange Unit(8번의 multi-scale fusion) 진행
- 실험에서 사용된 모델은 HRNet-W32(고해상도 서브네트워크 채널수가 32), HRNet-W48(고해상도 서브네트워크 채널수가 48) 두 가지 모델을 사용함
4. Experiments
4.1 COCO Keypoint Detection
- 본 논문에서 저자는 COCO train2017 데이터셋(57,000장 이미지, 150,000 인물 인스턴스)으로 모델을 학습하고 val2017, test-dev2017 데이터셋으로 평가를 진행함
- 평가지표는 객체 키포인트 유사도(Object Keypoint Similarity, OKS)를 활용함
- OKS란 predicted keypoint와 GT keypoint의 IoU(Intersection over Union)을 측정한다고 생각하면 이해가 빠를 것임

- OKS가 1에 가까울수록 keypoint 검출이 정확한 것이고, 0에 가까울수록 오차가 크다고 봐야함
- 논문에서 저자는 OKS의 AP(Average Precision)와 AR(Average Recall)을 측정하였음
- AP와 AR은 OKS 임계값을 바꿔가며 계산한 평균 Precision과 Recall을 의미함
- 즉, OKS를 이용해 AP(정확도)와 AR(재현율)를 계산하는 것이야.
- AP는 "정확히 맞춘 키포인트의 비율" (Precision 기반)
- AR은 "전체 중에서 맞춘 키포인트의 비율" (Recall 기반)

- HRNet이 bottom-up method들보다 월등하게 뛰어난 성능을 보였음
4.2 MPII Human Pose Estimation

- HRNet은 2018년 11월 16일 리더보드에서 기존 모델들 중 SOTA 모델과 동일한 성능을 보였음
- 저자는 그 이유를 MPII 데이터셋에 saturate되었기 때문이라고 짐작하였음
4.3 Application to Pose Tracking

- PoseTrack2017 데이터셋은 인간 자세추정과 비디오 연결 추적을 위한 데이터셋임
- HRNet은 기존 SOTA모델들과 비교했을 때, mAP와 MOTA에서 각각 0.3, 0.1 point 더 뛰어난 성능을 보였음
4.4 Ablation Study
Repeated multi-scale fusion이 네트워크 성능에 미치는 영향

- 저자는 multi-scale fusion가 네트워크 성능에 미치는 영향을 밝혀내기 위해 아래 세 가지 조건에서 실험을 진행함
- (a) 마지막 stage에서만 multi-scale fusion을 적용
- (b) stage 내에서는 multi-scale fusion이 없고 각 stage 간에만 fusion 적용
- (c) stage내, stage간에 multi-scale fusion 적용
- 실험결과 키포인트 유사도 AP가 (c)에서 가장 높았음
해상도 유지가 네트워크 성능에 미치는 영향
- 저자는 해상도 유지가 네트워크 성능에 미치는 영향을 밝혀내기 위해 아래 두 가지 조건에서 실험을 진행함
- 기존 HRNet: 점진적으로 저해상도를 subnetwork를 추가하는 방식
- 변형 네트워크: 초기에 모든 고-저해상도 서브 네트워크를 동시에 추가하고 동일한 깊이를 유지한 방식
- 실험결과 기존 HRNet은 AP 73.4, 변형 네트워크는 AP 72.5를 기록하였음
Representation 해상도가 네트워크 성능에 미치는 영향
- 저자는 representation 해상도가 네트워크 성능에 미치는 영향을 밝혀내기 위해 다음 두가지 실험을 진행함

해상도별 히트맵 성능 비교
- HRNet에서 출력되는 4가지 해상도의 히트맵 정확도를 각각 평가함
- 가장 낮은 해상도(가장 낮은 해상도 subnetwork)에서 생성된 히트맵은 성능이 매우 낮았으며, 10 이상 차이가 발생함
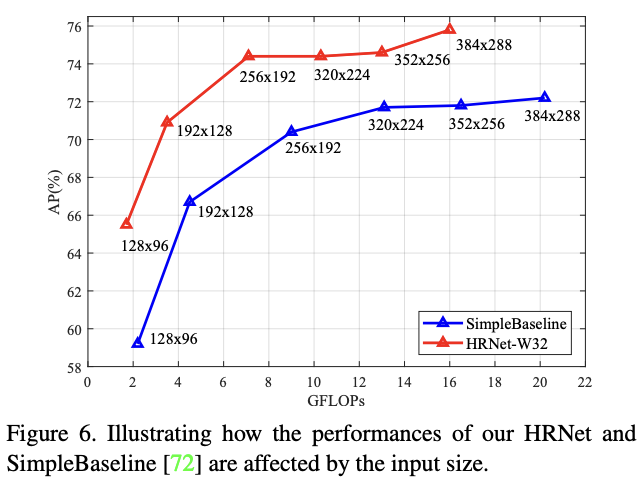
입력 이미지 크기에 따른 성능비교
- 입력 이미지 크기를 다르게 설정하고 HRNet과 Simplebaseline 모델을 비교함
- 결과적으로 입력 크기가 작을수록 HRNet의 성능 향상 폭이 더 큰것을 확인할 수 있음
- HRNet의 256x192 입력 해상도가 Simplebaseline의 가장큰 입력 해상도 결과보다 뛰어남
5. Conclusion
Hourglass, Simplebaseline 등의 기존 모델들이 다운샘플링 -> 업샘플링 하는 과정에서 세부(지역적인) 정보를 잃을 수 있다는 아이디어에서 시작한 논문이었습니다. 그래서 저자는 이러한 다운스캐일링, 업스캐일링 과정을 없애고 처음부터 끝까지 고해상도를 유지하면서 feature를 추출함으로써 세부정보 손실 없이 좋은 성능을 이끌어 냈습니다. 이 논문은 최근까지도 사람이나 동물 Pose Estimation 분야에서 많이 쓰일만큼 중요한 논문이므로 이후에는 이를 기반으로 한 변형논문들도 읽어볼 생각입니다.
'논문 리뷰' 카테고리의 다른 글
| [논문리뷰]CrowdPose : 군중 데이터에서 Pose Estimation (0) | 2025.03.20 |
|---|---|
| [논문리뷰]2D Human Pose Estimation: A Survey (0) | 2025.03.12 |
| [논문리뷰]Tracking Persons-of-Interest via Unsupervised Representation Adaptation: 제약없는 동영상에서 얼굴 추적 (0) | 2024.12.29 |
| [논문리뷰]FaceNet: Face Recognition의 기본모델 (2) | 2024.12.12 |
| [논문리뷰]UniDepth: 일반화된 Monocular Metric Depth Estimation! (2) | 2024.11.20 |