목차
안녕하세요 윤도현입니다. 오늘 소개할 논문은 2020년 IJCV에 개제된 Tracking Persons-of-Interest via Unsupervised Representation Adaptation 이라는 논문입니다. 제가 이 논문을 리뷰하는 이유는 최근 진행중인 사이드 프로젝트에서 Unconstrained(제약이 없는) 상황에서 Multi Face Tracking을 해야했기 때문입니다.
논문 리뷰에 앞서 이 논문을 한마디로 정리하면 다음과 같습니다.
카메라 앵글이나 장면 전환이 빈번하게 일어나는 Unconstrained Video에 특화된 Face Tracking model
1. Background
Constrained Video
Constrained Video를 한글로 직역하면 "제약이 없는 비디오"라는 뜻입니다. 여기서 말하는 제약이란 뭘까요?
바로 다음과 같은 제약조건을 말합니다.
- 장면 전환이 거의 이루어지지 않습니다.
- 카메라의 구도가 고정되어 있습니다.
- 카메라의 이동 속도가 느려 각도 및 구도의 변환이 천천히 이루어 집니다.
Constrained Video의 대표적인 예는 CCTV로 촬영된 Video입니다. CCTV는 특정한 위치에 고정되어 한 공간을 지속적으로 촬영하기 때문에 장면 전환이 이뤄지지 않고, 카메라의 구도가 고정되어 있습니다.

Unconstrained Video
반면에 Unconstrained Video, 즉 "제약이 없는 비디오"란 뭘까요?
앞서 말한 다양한 제약조건이 없는 비디오를 말합니다.
- 장면 전환이 빈번하게 일어나며, 장면 전환이 일어난 인접한 두 개의 프레임이 확연히 다릅니다.
- 여러 대의 움직이는 카메라로 비디오가 촬영되어 다양한 각도와 장면이 만들어집니다.
- 다른 장면에 동일 인물이 존재하더라도 크기, 각도, 포즈, 조명 조건 등에 의해 다양한 변화가 발생합니다.
Unconstrained Video의 대표적인 예는 TV 예능이나 드라마, 영화, 뮤직비디오 등 입니다. 이러한 비디오는 움직이는 여러 대의 카메라로 촬영하기 때문에 장면 전환이 빈번하게 이뤄지고, 다양한 구도와 각도에서 인물이 촬영됩니다. 따라서 지금까지 우리가 사용한 일반적인 Object Tracking model을 활용하면 ID Switching이 빈번하게 일어나서 Tracking 성능이 현저하게 떨어지는 것을 확인할 수 있습니다.
기존 모델들로 Unconstrained Video를 Inference하면 Tracking 성능이 떨어지는 이유를 좀 더 자세히 살펴보겠습니다.

2. Related Work and Problem Context
기존 방식(Tracking by Detection)
- 비디오가 입력되면 매 프레임마다 Object Detection 진행
- Detection된 bbox와 칼만 필터를 이용하여 다음 위치를 예측
- 예측된 bbox와 실제 bbox의 IoU 유사도를 비교하여 같은 Object 라고 판단되는 bbox들을 연결하여 Trajectory 생성
✔️ Kalman filter를 이용하여 이전 프레임에 등장한 개체를 바탕으로 다음 프레임의 개체의 위치를 예측하고 측정

예를들어, 동영상 frame에서 움직이는 공을 추적한다고 가정해보겠습니다.
- 예측 상태 추정(Predicted State Estimate):이전 프레임에서 공의 위치와 속도 정보를 기반으로, 현재 프레임에서 공의 위치를 예측합니다.예를 들어, 이전 프레임에서 공이 (100, 150) 좌표에 있었고, x축 방향으로 초당 5픽셀, y축 방향으로 초당 3픽셀의 속도로 움직이고 있었다면, 1초 후에는 (105, 153) 좌표에 있을 것으로 예측합니다.
- 측정값(Measurement):현재 프레임에서 영상 처리 알고리즘(예: 객체 검출 알고리즘)을 통해 실제로 감지된 공의 위치입니다.예를 들어, 현재 프레임에서 객체 검출 알고리즘이 공의 위치를 (106, 152)로 감지했다면, 이 좌표가 측정값이 됩니다.
칼만 필터의 동작:
예측 단계(Prediction):이전 상태(위치와 속도)를 기반으로 현재 상태를 예측합니다.위 예시에서는 (105, 153)으로 예측되었습니다.갱신 단계(Update):실제 측정값((106, 152))과 예측값((105, 153))을 비교하여 오차를 계산합니다.이 오차를 바탕으로 예측값을 보정하여 최종 추정값을 얻습니다.예를 들어, 보정된 최종 추정 위치가 (105.5, 152.5)로 계산될 수 있습니다.
이처럼 기존 방식은 물체의 현재 위치와 가속도(x,y,z 방향)를 이용하여 예측하기 때문에 Constrained Video와 같이 물체가 연속적으로 검출(detection)되고 카메라가 고정되어 있을 때 효과적입니다. 하지만 Unconstrained Video는 카메라 앵글이 빠르게 바뀌고 장면전환도 빈번하게 이뤄지기 때문에 성능이 떨어질 수 밖에 없었습니다.
Contribution
본 논문의 주요 기여 항목은 다음과 같습니다.
- Contextual constraints(맥락적 제약)을 통해 자동으로 발견된 샘플에 대한 deep contrastive(심층 대조) 및 triplet-based metric learning으로 얼굴의 큰 외관 변화를 설명하였습니다.
- 개선된 Triplet Loss function인 Sym-Triplet을 소개하였습니다.
- 이전 논문들이 False Positives를 수동으로 제거한 Face Track를 사용한 반면, 본 논문은 Raw Video를 입력값으로 사용하였습니다.
- YouTube에서 8개의 새로운 뮤직비디오 데이터 셋을 구축하여 Unconstrained Video에서의 Multi Face Tracking 성능을 평가하였습니다.
- DukeMTMC 데이터 셋을 활용하여 본 논문이 얼굴뿐만 아니라 보행자 등의 다른 Object를 Tracking 할 수 있음을 보여주었습니다.
3. ALGORITHMIC OVERVIEW

그림은 다소 복잡하게 나와있지만 크게 3단계로 정리할 수 있습니다.
- 동영상을 입력받아 scene change detection하고 전체 동영상을 여러 장면(scene)으로 나누기
(이때 각 장면은 여러개의 frame으로 구성되어 있습니다.) - 각각의 장면(여러 frame)을 입력받아 Face Detection + Tracking(논문에서는 deepsort 계열 사용)을 사용하여 tracklet 생성
- tracklet 들을 서로 연결하여 trajectory 생성
A. Supervised Pre-training
- AlexNet architecture를 CASIA-WebFace dataset으로 training 하였습니다.
- 9,427명을 골랐으며 dataset의 80%는 training set으로, 나머지 20%는 validation set으로 구성하였습니다.
- 각 얼굴 이미지는 227 x 227 x 3 픽셀로 정규화되었습니다.
- Caffe toolbox를 사용하여 20,000번 반복할 때마다 10배씩 감소하는 초기 learning rate가 0.01인 확률적 경사 하강법(SGD)를 사용하였습니다.
B. Discovering Training Samples
- Shot detection and tracklets linking
- Shot Change Detection(장면 전환 탐지) 방법을 활용하여 비디오를 장면 별로 분할해 줍니다.
- 두 개의 임곗값(two-threshold) 방법을 이용해 각 프레임별로 Face Detection을 진행합니다. (two-threshold strategy는 더 좋은 방법으로 대체될 수 있습니다.)
- 외관, 위치, 크기의 유사도에 기반하여 인접한 프레임의 Face Detection Box를 연결하여 Tracklet을 생성합니다.
- 5 프레임보다 짧은 Tracklet은 삭제됩니다.
2. Spatio-temporal constraints
Tracklet의 집합을 사용하여 동일 인물 혹은 다른 인물에 속하는 positive 혹은 negative training sample 쌍의 large collection을 발견할 수 있습니다.
- Positive pair: 하나의 Tracklet에 있는 모든 쌍의 얼굴은 한 사람의 것입니다.
- Negative pair: 같은 프레임에 나타나는 두 개의 얼굴 tracklet에는 다른 사람의 얼굴이 포함되어 있습니다.
Spatio-temporal Constraints(시공간 제약)만을 사용하였을 때는 두 가지의 문제점이 생길 수 있습니다.
- Positive 얼굴 쌍은 종종 모양 변형이 작습니다.
- Negative 얼굴 쌍은 모두 동일한 장면에서 동시에 발생하는 Tracklet에서 생성되어 다른 장면에서 생성된 동일한 얼굴을 구분하거나 연결하기 어렵습니다.
이러한 문제점들을 해결하기 위하여 Contextual Constraints를 사용합니다.
3. Contextual constraints

얼굴 특징만을 활용하는 것이 아니라 옷의 특징도 함께 활용하여 Tracking을 진행하는 것을 의미합니다.
위의 뮤직비디오처럼 처음부터 끝까지 등장인물이 같은 옷을 입고 등장한다면 얼굴 특징만을 활용하는 것보다 인물 구분을 훌륭하게 잘 해내지만, 장면이 전환되었을 때 같은 인물이 다른 옷을 입고 있다면 오히려 Face feature가 비슷해도 옷의 feature 때문에 인물 구분을 정확히 해내지 못한다는 단점이 존재합니다.
C. Learning Adaptive Discriminative Features
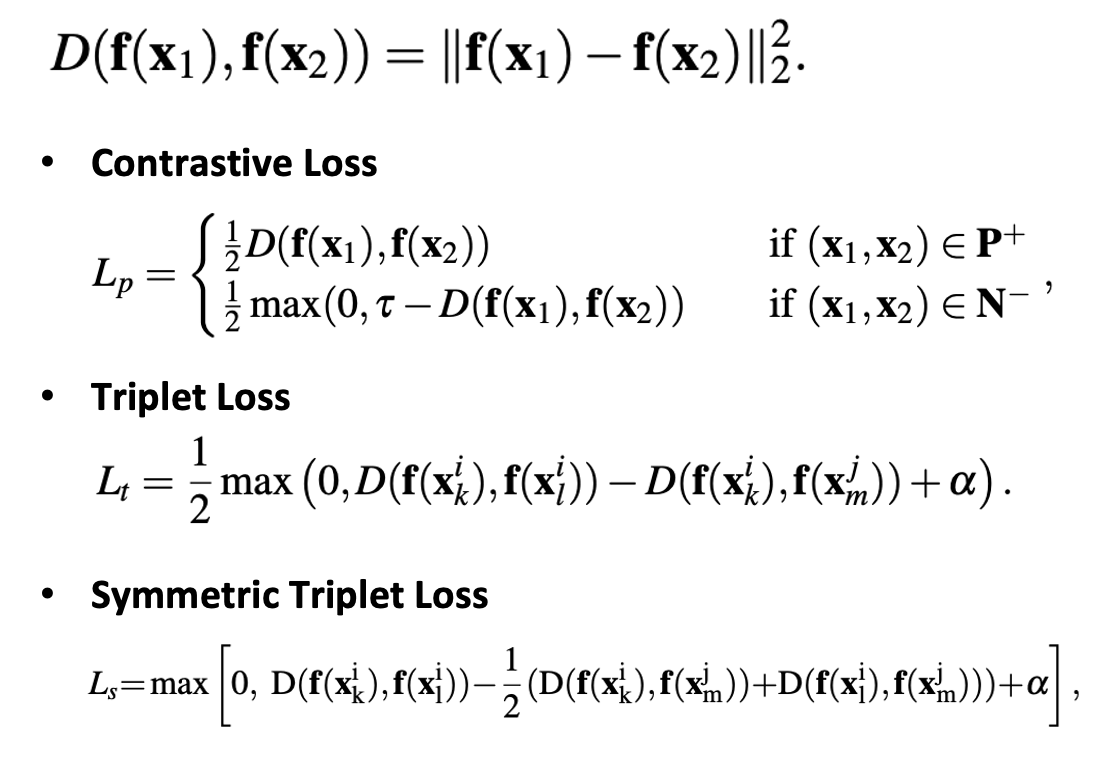
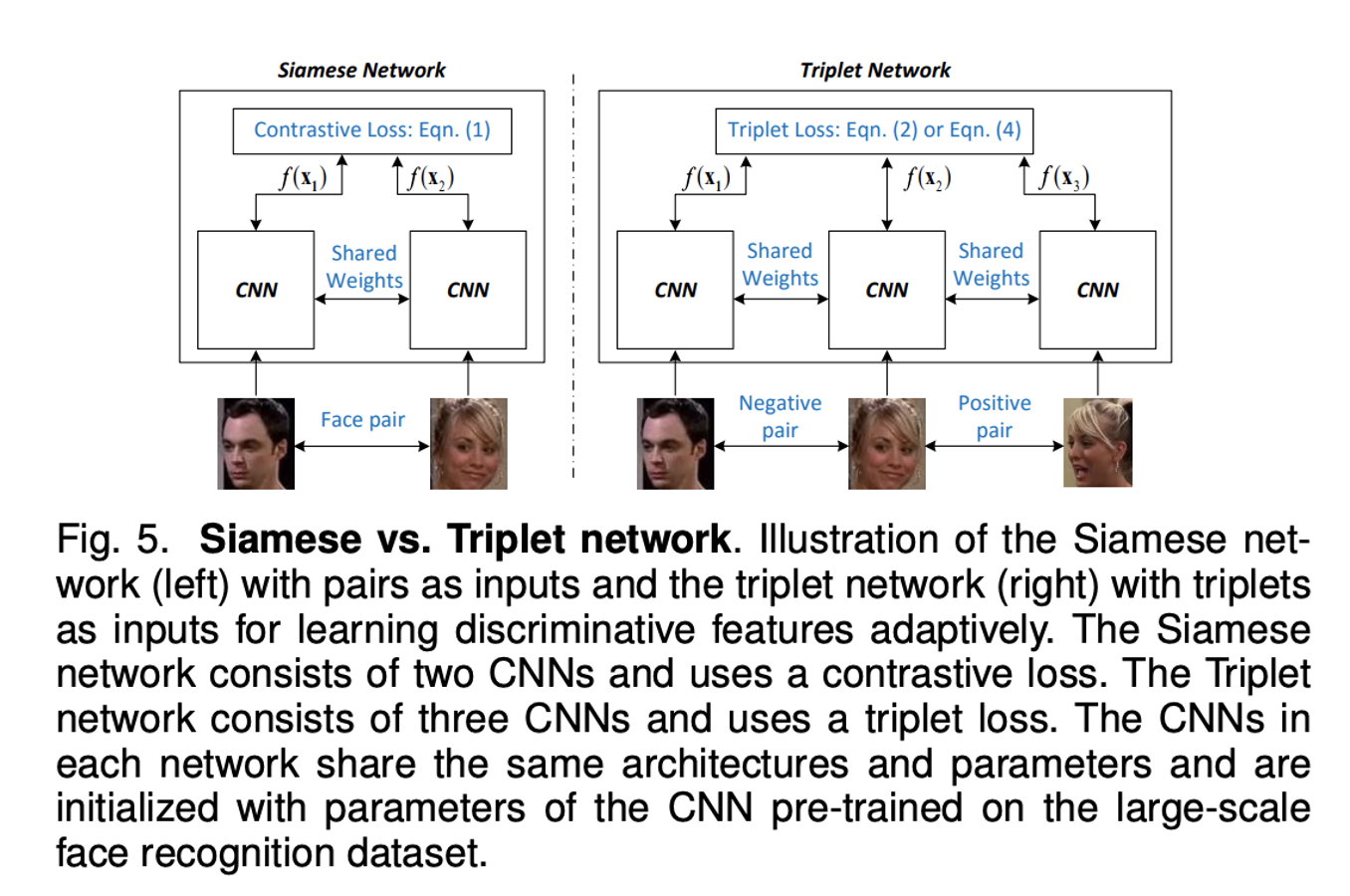
본 논문에서는 Discriminative Feature를 학습하기 위해 사용되는 세 가지의 Loss를 소개하였습니다.
- Contrastive Loss
Constrastive Loss는 그림 좌측 및 위의 식에서 확인할 수 있듯이 비슷한 특징을 가진 두 얼굴은 Positive Pair로, 그렇지 않은 두 얼굴은 Negative Pair로 분류합니다.
2. Triplet Loss
Triplet Loss는 비슷한 특징을 가진 두 얼굴은 서로 가깝게, 그렇지 않은 두 얼굴은 서로 멀어지게 하여 학습을 시킵니다. 하단의 그림에서 같은 사람의 얼굴은 원으로, 다른 사람의 얼굴은 세모로 표현하였습니다.
3. Symmetric Triplet Loss
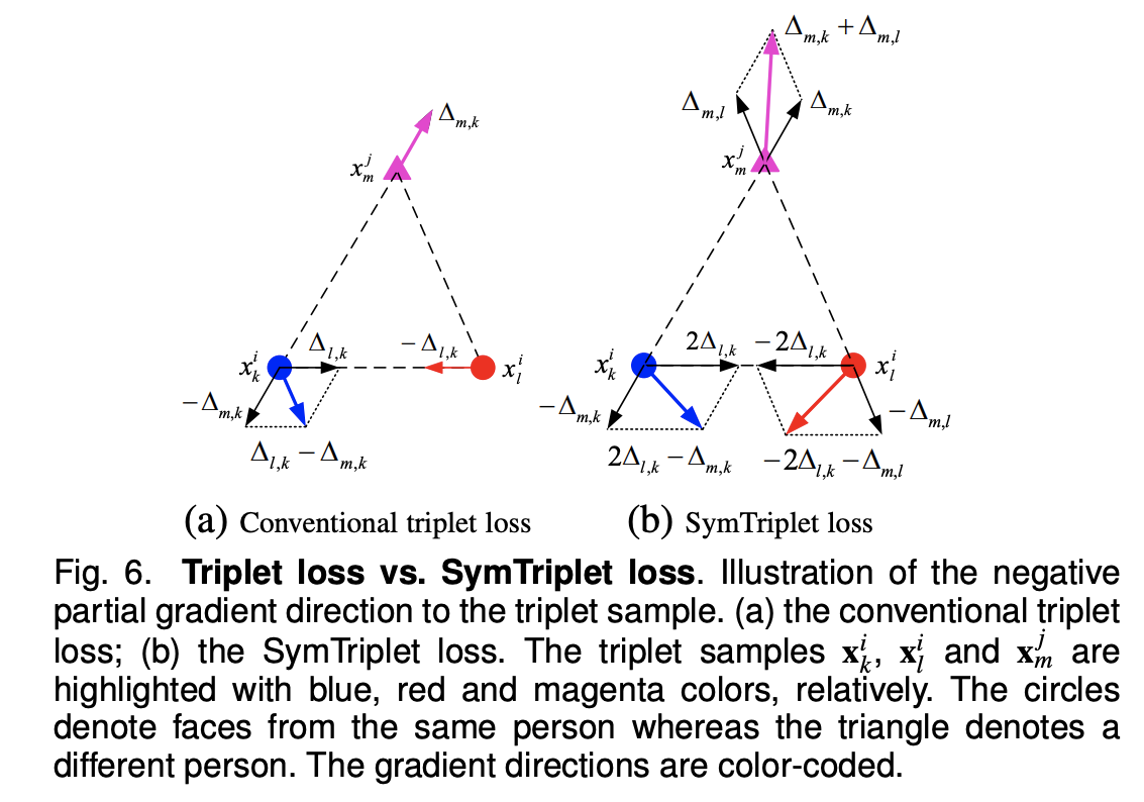
Symmetric Triplet Loss(SymTriplet Loss)는 본 논문의 저자들이 Triplet Loss의 문제점을 지적하고 수정한 Loss Function입니다. 기존의 Triplet Loss는 좌측 그림에서 파악할 수 있듯이, 파란색 원과 마젠타의 특징 비교는 진행됐지만 빨간색 원과 마젠타는 그렇지 않은 것을 확인할 수 있습니다.
SymTriplet Loss는 모든 얼굴 사이의 Feature를 비교하여 더 확실한 Discriminative Feature를 학습할 수 있도록 하였습니다.
D. Linking Tracklets
Adaptive Discriminative Feature를 학습한 후에 획득한 Tracklet을 연결하여 최종 얼굴 Trajectories를 획득할 수 있습니다.
- 같은 장면 안에 존재하는 Tracklet을 연결합니다.
학습된 Deep Network를 사용하여 Face Detection Box에서 Feature를 추출한 후, 시간, 운동학 및 외관 정보를 사용하여 Tracklet 사이의 연결 확률을 측정합니다. 그 후 Hungarian Algorithm을 사용하여 동일한 Label의 Tracklet을 연결합니다. - 장면 사이의 Tracklet을 연결합니다.
Experiments
Datasets
- Frontal Video
- BBT dataset: 미국 TV 시트콤 “빅뱅 이론”
- BUFFY dataset: 미국 TV 시트콤 “The Buffy the Vampire slayer”
- YouTube에서 수집한 Music Video dataset
Evaluation Metrics
- Weighted Purity: 클러스터링의 품질을 측정합니다.
- CLEAR MOT: Multi Object Tracking에서 주로 사용되는 측정 기법입니다. Recall, Precision, F1, FAF, IDs, Frag, MOTA, MOTP 등을 측정합니다.
Results
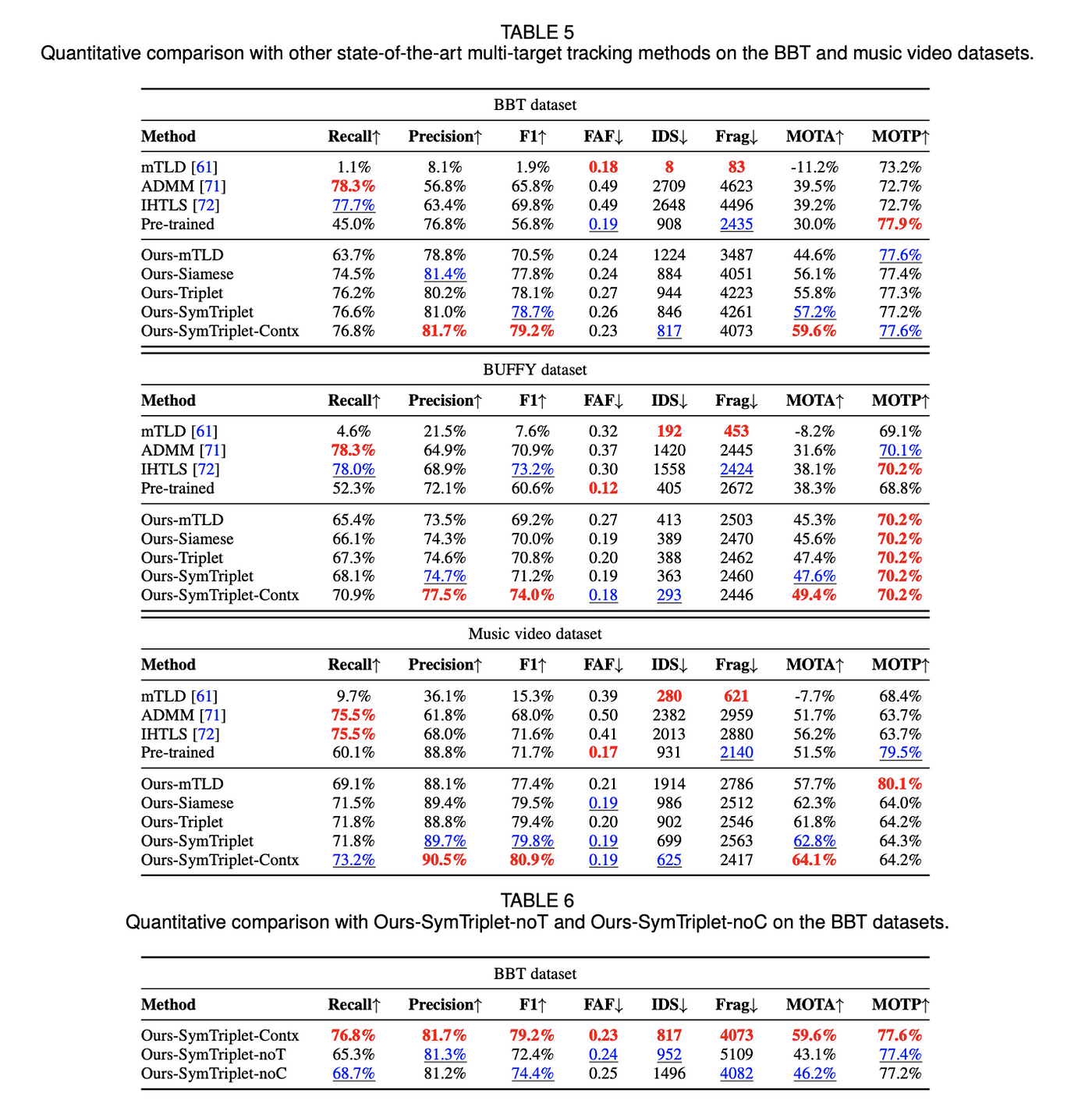
MOTA 값이 평가에서 가장 중요한 요소인데, 논문에서 제안한 방법의 MOTA 값이 제일 높은 것을 확인할 수 있습니다.
또한 Contrastive, Triplet, SymTriplet 세 가지 Loss Function을 적용하여 비교한 실험 결괏값이 존재하는데, 논문에서 제안한 SymTriplet의 성능이 제일 잘 나오는 것을 확인할 수 있습니다.


실제로 Bounding Box를 출력해 본 결괏값은 다음과 같습니다. ID가 초반 Frame부터 후반 Frame까지 큰 변화 없이 유지되는 것을 확인할 수 있습니다.
'논문 리뷰' 카테고리의 다른 글
| FaceNet: Face Recognition의 기본모델 (2) | 2024.12.12 |
|---|---|
| UniDepth: 일반화된 Monocular Metric Depth Estimation! (0) | 2024.11.20 |
| [논문리뷰]Co-DETR: LVIS 데이터셋 SOTA (2) | 2024.10.16 |
| [논문리뷰]RawHDR: Raw 데이터로부터 HDR 이미지 복원하기 (4) | 2024.09.25 |
| [논문리뷰]Replacing Mobile Camera ISP: 딥러닝으로 ISP 대체하기 (0) | 2024.09.05 |