목차
2021년 7월 27일 기준 작성된 글입니다. 수정사항이 있으면 댓글로 말씀 부탁드립니다.
https://github.com/dohyeonYoon/yolov4-custom-training
GitHub - dohyeonYoon/yolov4-custom-training: google colab을 이용한 yolov4 custom dataset training
google colab을 이용한 yolov4 custom dataset training. Contribute to dohyeonYoon/yolov4-custom-training development by creating an account on GitHub.
github.com
1. Google Colab 실행

2. 런타임 유형변경
GPU 사용을 위해 런타임 유형을 GPU로 변경하고 우측상단에 연결 버튼을 눌러줍니다


3. 구글드라이브에 yolov4 폴더를 생성하고 그 안에 training 폴더를 생성합니다

4. 구글드라이브를 colab에 마운트 시켜줍니다.
%cd ..
from google.colab import drive
drive.mount('/content/gdrive')
폴더연결 (다음 명령어를 실행하여 /content/gdrive/My\drive/ 경로가 /mydrive와 같도록 심볼릭 링크를 만듭니다)
!ln -s /content/gdrive/My\ Drive/ /mydrive
yolov4 폴더로 이동
%cd /mydrive/yolov4
5. Darknet git repository를 yolov4 폴더에 clone
!git clone https://github.com/AlexeyAB/darknet
clone하면 다음과같이 yolov4 하위폴더에 darknet이 생성된것을 볼 수 있습니다.
6. 다음의 파일들을 생성 및 업로드 합니다.(custom training을 위해 필요)
a. 라벨링된 데이터셋
b. yolov4-custom.cfg 파일
c. obj.data , obj.names 파일
d. process.py 파일 (darknet/data/ 폴더에 train.txt, test.txt 파일을 생성해줌)
라벨링된 데이터셋

yolo mark나 labelimg를 이용해 yolo형식으로 저장하였다면 다음과 같은 형식으로 txt파일이 생성되었을 것입니다.
해당 파일들이 있는 폴더를 obj.zip 파일로 압축하여 yolov4 폴더에 넣어줍니다.
yolov4-custom.cfg 파일
구글드라이브 yolov4/darknet/cfg 폴더에 들어가면
yolov4-custom.cfg 파일이 있습니다.
해당 파일을 다운로드한 뒤 열고
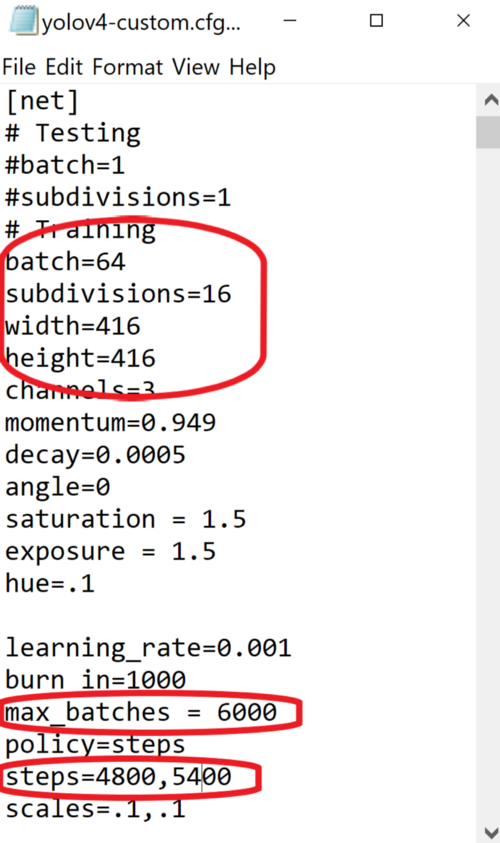
동그라미 친 부분을 다음과 같이 수정합니다
max_batches = (class 갯수 *2000 ) "만약 class가 2개라면 4000입니다"
steps = max_batches*0.8 , max_batches*0.9 로 수정해줍니다

txt 파일에서 Ctral+f 를 눌러 yolo를 검색하면 총 3개의 yolo 부분이 있는데
[yolo] 바로 위에있는 [convolutional] 부분에서 filters = (class갯수+5)*3 로 수정해줍니다 "만약 class가 2개면 21 이겠죠?"
[yolo] 부분에서 classes = 클래수 갯수로 수정해줍니다
이 작업을 3번 반복해줍니다 .
수정을 마치면 yolov4 폴더에 넣어주세요!
obj.data 파일
classes = 2
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = /mydrive/yolov4/training다음과 같이 obj.data 파일을 yolov4 폴더에 만들어줍니다. 아래 깃허브에서 다운받아도 됩니다
https://github.com/dohyeonYoon/yolov4-custom-training
GitHub - dohyeonYoon/yolov4-custom-training: google colab을 이용한 yolov4 custom dataset training
google colab을 이용한 yolov4 custom dataset training. Contribute to dohyeonYoon/yolov4-custom-training development by creating an account on GitHub.
github.com
obj.names 파일
helmet
no_helmet이렇게 본인이 원하는 class 이름들을 적어주고 yolov4 폴더에 생성해줍니다
process.py 파일
해당 파일을
https://github.com/dohyeonYoon/yolov4-custom-training
GitHub - dohyeonYoon/yolov4-custom-training: google colab을 이용한 yolov4 custom dataset training
google colab을 이용한 yolov4 custom dataset training. Contribute to dohyeonYoon/yolov4-custom-training development by creating an account on GitHub.
github.com
깃허브에서 다운받고 yolov4 폴더에 업로드 해줍니다
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
print(current_dir)
current_dir = 'data/obj'
# Percentage of images to be used for the test set
percentage_test = 10;
# Create and/or truncate train.txt and test.txt
file_train = open('data/train.txt', 'w')
file_test = open('data/test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write("data/obj" + "/" + title + '.jpg' + "\n")
else:
file_train.write("data/obj" + "/" + title + '.jpg' + "\n")
counter = counter + 1yolov4/darknet/data/obj 폴더에 있는 데이터셋 파일들을 train.txt, test.txt 파일에 경로+파일이름 으로 내용삽입해주는 스크립트

여기까지 완료되면 다음과 같이 폴더가 구성되어야함 !!!!
7. makefile 수정(OpenCV, GPU 사용을 위한)
%cd darknet/
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
!sed -i 's/LIBSO=0/LIBSO=1/' Makefiledarknet build를 위한 명령어
!make
8. yolov4 폴더에 있는 파일들을 darknet 디렉토리로 복사
darknet/data 폴더 내 모든파일 삭제 + darknet/cfg 폴더 삭제
%cd data/
!find -maxdepth 1 -type f -exec rm -rf {} \;
%cd ..
%rm -rf cfg/
%mkdir cfgdarknet/data 폴더에 obj 폴더 생성하고 해당폴더에 데이터셋 압축풀기
!unzip /mydrive/yolov4/obj.zip -d data/objyolov4-custom.cfg 파일을 darknet/cfg 폴더에 복사
!cp /mydrive/yolov4/yolov4-custom.cfg cfgobj.data, obj.names 파일을 darknet/data 폴더에 복사
!cp /mydrive/yolov4/obj.names data
!cp /mydrive/yolov4/obj.data dataprocess.py 파일을 darknet 디렉토리에 복사
!cp /mydrive/yolov4/process.py .process.py 파일 실행하여 train.txt, test.txt 파일 생성
!python process.py
9. pretrain된 yolov4 weight 파일 다운로드
여기서 전이학습을 사용합니다. 모델을 처음부터 훈련하는 대신 최대 137개의 convolution layer까지 훈련된 사전훈련 가중치 파일을 사용합니다.
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
10. Training
본인의 custom training dataset을 미리 학습된 yolov4.conv.137 가중치 파일에 전이학습합니다
!./darknet detector train data/obj.data cfg/yolov4-custom.cfg yolov4.conv.137 -dont_show -map
만약 training중 예기치않게 학습이 중지되었다면
- 드라이브 마운트
- makefile 수정
- !make 로 darknet build
이 세가지만 다시 실행한다음에 다음의 명령어를 실행합니다
!./darknet detector train data/obj.data cfg/yolov4-custom.cfg /mydrive/yolov4/training/yolov4-custom_last.weights -dont_show -map
11. Test
imShow 함수 정의
# function imShow define
def imShow(path):
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread(path)
height, width = image.shape[:2]
resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC)
fig = plt.gcf()
fig.set_size_inches(18, 10)
plt.axis("off")
plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))
plt.show()
yolov4-custom.cfg 파일에서 batch =1 ,subdivisions=1 로 수정
%cd cfg
!sed -i 's/batch=64/batch=1/' yolov4-custom.cfg
!sed -i 's/subdivisions=16/subdivisions=1/' yolov4-custom.cfg
%cd ..
1. 이미지에서 yolov4 detector 실행
먼저 mydrive 에 kickboard_test_images 폴더를 만들고 테스트 이미지 넣어주기!!
!./darknet detector test data/obj.data cfg/yolov4-custom.cfg /mydrive/yolov4/training/yolov4-custom_best.weights /mydrive/kickboard_test_images/image1.jpg -thresh 0.3
imShow('predictions.jpg')
2. video에서 yolov4 detector 실행
mydrive에 kickboard_test_videos 폴더 생성하고 테스트 비디오 넣기
!./darknet detector demo data/obj.data cfg/yolov4-custom.cfg /mydrive/yolov4/training/yolov4-custom_best.weights -dont_show /mydrive/mask_test_videos/test1.mp4 -thresh 0.5 -i 0 -out_filename /mydrive/kickboard_test_videos/results1.avi
3. live webcam에서 yolov4 detector 실행
# import dependencies
from IPython.display import display, Javascript, Image
from google.colab.output import eval_js
from google.colab.patches import cv2_imshow
from base64 import b64decode, b64encode
import cv2
import numpy as np
import PIL
import io
import html
import time
import matplotlib.pyplot as plt
%matplotlib inline
# import darknet functions to perform object detections
from darknet import *
# load in our YOLOv4 architecture network
network, class_names, class_colors = load_network("cfg/yolov4-custom.cfg", "data/obj.data", "/mydrive/yolov4/training/yolov4-custom_best.weights")
width = network_width(network)
height = network_height(network)
# darknet helper function to run detection on image
def darknet_helper(img, width, height):
darknet_image = make_image(width, height, 3)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = cv2.resize(img_rgb, (width, height),
interpolation=cv2.INTER_LINEAR)
# get image ratios to convert bounding boxes to proper size
img_height, img_width, _ = img.shape
width_ratio = img_width/width
height_ratio = img_height/height
# run model on darknet style image to get detections
copy_image_from_bytes(darknet_image, img_resized.tobytes())
detections = detect_image(network, class_names, darknet_image)
free_image(darknet_image)
return detections, width_ratio, height_ratio
# function to convert the JavaScript object into an OpenCV image
def js_to_image(js_reply):
"""
Params:
js_reply: JavaScript object containing image from webcam
Returns:
img: OpenCV BGR image
"""
# decode base64 image
image_bytes = b64decode(js_reply.split(',')[1])
# convert bytes to numpy array
jpg_as_np = np.frombuffer(image_bytes, dtype=np.uint8)
# decode numpy array into OpenCV BGR image
img = cv2.imdecode(jpg_as_np, flags=1)
return img
# function to convert OpenCV Rectangle bounding box image into base64 byte string to be overlayed on video stream
def bbox_to_bytes(bbox_array):
"""
Params:
bbox_array: Numpy array (pixels) containing rectangle to overlay on video stream.
Returns:
bytes: Base64 image byte string
"""
# convert array into PIL image
bbox_PIL = PIL.Image.fromarray(bbox_array, 'RGBA')
iobuf = io.BytesIO()
# format bbox into png for return
bbox_PIL.save(iobuf, format='png')
# format return string
bbox_bytes = 'data:image/png;base64,{}'.format((str(b64encode(iobuf.getvalue()), 'utf-8')))
return bbox_bytes
# JavaScript to properly create our live video stream using our webcam as input
def video_stream():
js = Javascript('''
var video;
var div = null;
var stream;
var captureCanvas;
var imgElement;
var labelElement;
var pendingResolve = null;
var shutdown = false;
function removeDom() {
stream.getVideoTracks()[0].stop();
video.remove();
div.remove();
video = null;
div = null;
stream = null;
imgElement = null;
captureCanvas = null;
labelElement = null;
}
function onAnimationFrame() {
if (!shutdown) {
window.requestAnimationFrame(onAnimationFrame);
}
if (pendingResolve) {
var result = "";
if (!shutdown) {
captureCanvas.getContext('2d').drawImage(video, 0, 0, 640, 480);
result = captureCanvas.toDataURL('image/jpeg', 0.8)
}
var lp = pendingResolve;
pendingResolve = null;
lp(result);
}
}
async function createDom() {
if (div !== null) {
return stream;
}
div = document.createElement('div');
div.style.border = '2px solid black';
div.style.padding = '3px';
div.style.width = '100%';
div.style.maxWidth = '600px';
document.body.appendChild(div);
const modelOut = document.createElement('div');
modelOut.innerHTML = "<span>Status:</span>";
labelElement = document.createElement('span');
labelElement.innerText = 'No data';
labelElement.style.fontWeight = 'bold';
modelOut.appendChild(labelElement);
div.appendChild(modelOut);
video = document.createElement('video');
video.style.display = 'block';
video.width = div.clientWidth - 6;
video.setAttribute('playsinline', '');
video.onclick = () => { shutdown = true; };
stream = await navigator.mediaDevices.getUserMedia(
{video: { facingMode: "environment"}});
div.appendChild(video);
imgElement = document.createElement('img');
imgElement.style.position = 'absolute';
imgElement.style.zIndex = 1;
imgElement.onclick = () => { shutdown = true; };
div.appendChild(imgElement);
const instruction = document.createElement('div');
instruction.innerHTML =
'<span style="color: red; font-weight: bold;">' +
'When finished, click here or on the video to stop this demo</span>';
div.appendChild(instruction);
instruction.onclick = () => { shutdown = true; };
video.srcObject = stream;
await video.play();
captureCanvas = document.createElement('canvas');
captureCanvas.width = 640; //video.videoWidth;
captureCanvas.height = 480; //video.videoHeight;
window.requestAnimationFrame(onAnimationFrame);
return stream;
}
async function stream_frame(label, imgData) {
if (shutdown) {
removeDom();
shutdown = false;
return '';
}
var preCreate = Date.now();
stream = await createDom();
var preShow = Date.now();
if (label != "") {
labelElement.innerHTML = label;
}
if (imgData != "") {
var videoRect = video.getClientRects()[0];
imgElement.style.top = videoRect.top + "px";
imgElement.style.left = videoRect.left + "px";
imgElement.style.width = videoRect.width + "px";
imgElement.style.height = videoRect.height + "px";
imgElement.src = imgData;
}
var preCapture = Date.now();
var result = await new Promise(function(resolve, reject) {
pendingResolve = resolve;
});
shutdown = false;
return {'create': preShow - preCreate,
'show': preCapture - preShow,
'capture': Date.now() - preCapture,
'img': result};
}
''')
display(js)
def video_frame(label, bbox):
data = eval_js('stream_frame("{}", "{}")'.format(label, bbox))
return data
# start streaming video from webcam
video_stream()
# label for video
label_html = 'Capturing...'
# initialze bounding box to empty
bbox = ''
count = 0
while True:
js_reply = video_frame(label_html, bbox)
if not js_reply:
break
# convert JS response to OpenCV Image
frame = js_to_image(js_reply["img"])
# create transparent overlay for bounding box
bbox_array = np.zeros([480,640,4], dtype=np.uint8)
# call our darknet helper on video frame
detections, width_ratio, height_ratio = darknet_helper(frame, width, height)
# loop through detections and draw them on transparent overlay image
for label, confidence, bbox in detections:
left, top, right, bottom = bbox2points(bbox)
left, top, right, bottom = int(left * width_ratio), int(top * height_ratio), int(right * width_ratio), int(bottom * height_ratio)
bbox_array = cv2.rectangle(bbox_array, (left, top), (right, bottom), class_colors[label], 2)
bbox_array = cv2.putText(bbox_array, "{} [{:.2f}]".format(label, float(confidence)),
(left, top - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
class_colors[label], 2)
bbox_array[:,:,3] = (bbox_array.max(axis = 2) > 0 ).astype(int) * 255
# convert overlay of bbox into bytes
bbox_bytes = bbox_to_bytes(bbox_array)
# update bbox so next frame gets new overlay
bbox = bbox_bytes'Computer Vision > Object Detection' 카테고리의 다른 글
| [Detection] Yolov5 custom dataset 학습 및 추론방법 (4) | 2022.04.25 |
|---|---|
| [Detection+Tracking] YOLOv4+Deep_SORT custom model 사용법 (5) | 2021.08.09 |
| YOLO v4 모델 사용방법 (2) | 2021.07.22 |